ACPの認知度は22.3%
ACP (Advanced Care Planning) の認知度は22.3%という調査結果が厚生労働省のホームページに掲載されました。

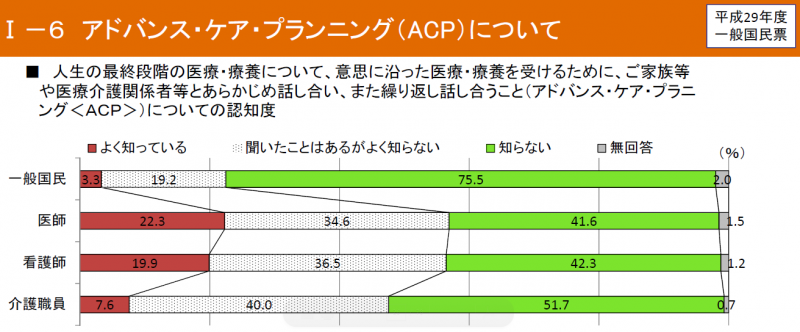
ACPの認知度は22.3%
ACP (Advanced Care Planning) の認知度は22.3%という調査結果が厚生労働省のホームページに掲載されました。
> library(Rcpp)
library(Rcpp) でエラー: ‘Rcpp’ という名前のパッケージはあり
インストールを3回試してみて、ダメでした。ダメだった時のログですが、有用なエラーメッセージはありません。コンソールを見ている限り何がダメなのかわかりません。
install.packages(‘Rcpp’)
パッケージを ‘C:/Users/Oshima/Documents/R/win-library/3.3’ 中にインストールします
(‘lib’ が指定されていないため)
— このセッションで使うために、CRAN のミラーサイトを選んでください —
URL ‘https://cloud.r-project.org/bin/windows/contrib/3.3/Rcpp_0.12.15.zip’ を試しています
Content type ‘application/zip’ length 4357370 bytes (4.2 MB)
downloaded 4.2 MBパッケージ ‘Rcpp’ は無事に展開され、MD5 サムもチェックされました
ダウンロードされたパッケージは、以下にあります
C:\______\Local\Temp\RtmpUfqmSC\downloaded_packages
しばらくやった後、これは、先人も経験があるはずと調べたところ、それらしい記事に当たりました。リンク先の柴田啓文先生、ありがとうございます。
セキュリティソフトを10分間無効にしてインストールすると、わたしも成功しました。
一寸試そうとしたが、よくわからなくなって来たから、少し戻って仕切り直しが必要だな。
楽曲の元になったと思われるKomitas (Gomidas)の曲集を見つけたので、スクリーンショットをまとめてみました。
(スクリーンショットは表示されたりされなかったりがあるので、曲集のダウンロードリンクも作成しました。)
VOICES OF ARMENIA (Geghard Ensemble, Pahayan)
Podcast: Play in new window | Download
先週職場近くのアルメニア共和国??大使館に行った!と言う話を職場でしていたら、近くなら行きたいと言う同僚たちが出てきたので、再び訪問しました。
今回は対応する係の人が少し説明してくださって、意外なことに(失礼)街には地下鉄がある事、国境線が未確定な部分が多い事、アララト山は隣国のトルコ領である事などなどお話しくださいました。 パスポートと称すスタンプ帳は前回訪問時にスタンプを押してもらったので、今回は30年以上前に演奏した、この曲のスコアを持って行って、ペッタン!しました。

iPodから送信
医療仮想主義者、なかなか面白い言葉です。
病院に行ったら、「変なホテル」みたいにロボットが受け付けして、診察室にも医者型ロボットがいて、ルーチンでさばけるような特に問題のなさそうな奴は本当の医者の診察抜きで投薬するとか。あるいは、そこまでの機能だと、街角の自動販売機型の病院でスクリーニングして必要なら自動販売機で本当の施設を予約するとか…あ、回転ずしのペッパー君みたいだ
12月のデュトワは難しいのかな?

iPodから送信
これは誰かな?
ここを通りながら菊池寛美術館と読んでいました。書斎の様子が再現してあったり、使っていたペンが展示してあったり、を想像してました。

iPodから送信





