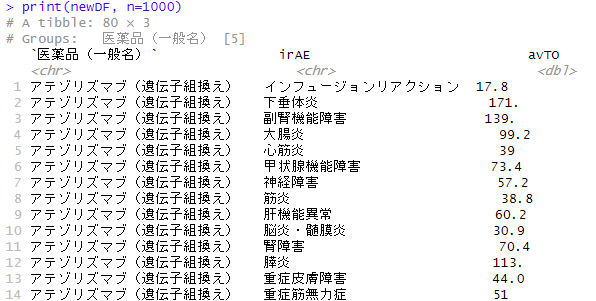
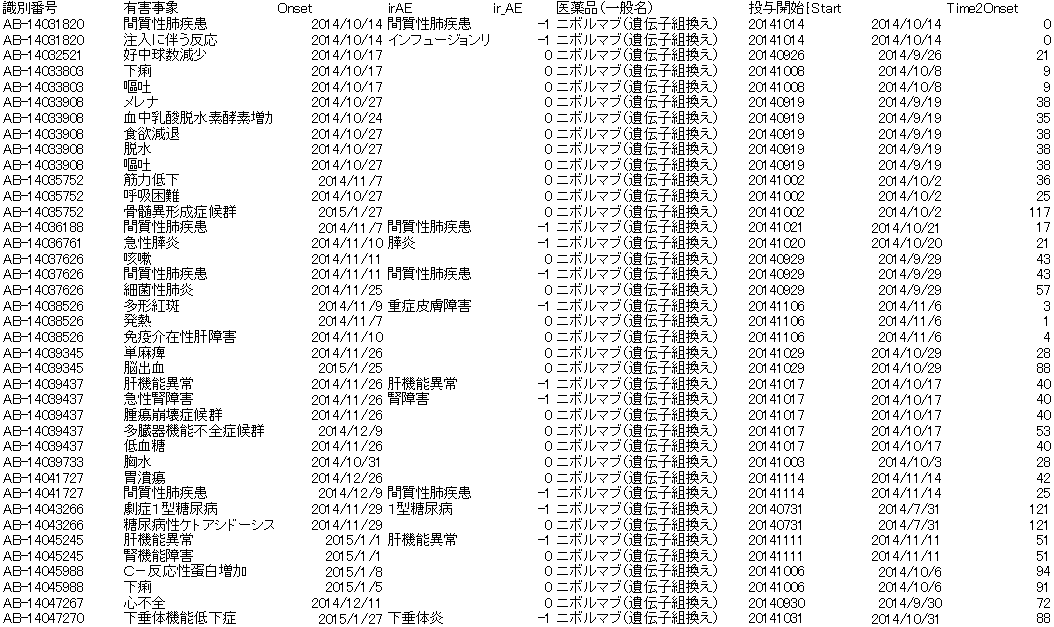
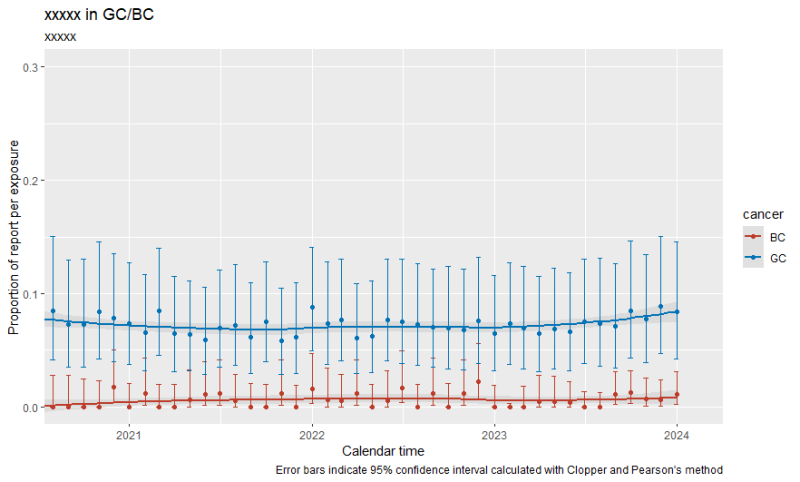
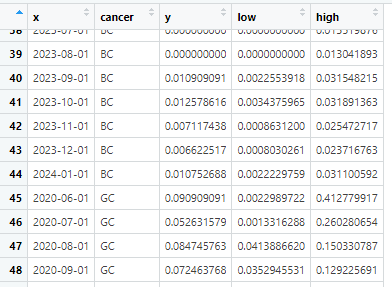
epibasixパッケージの関数を試して見ました
sensSpec関数
このRコードは、疫学研究において新しい検査法や自己報告を現行のゴールドスタンダードと比較する際に、感度、特異度、Youden指数、および一致率を計算するためのものです。
library(epibasix) # This function is designed to calculate Sensitivity, Specificity, Youden’s J and Percent Agreement. # These tools are used to assess the validity of a new instrument or self-report against the current # gold standard. In general, self-report is less expensive, but may be subject to information bias. # Computational formulae can be found in the reference. dat <- cbind(c(18,1), c(19,11)) summary(sensSpec(dat)) # Szklo M and Nieto FJ. Epidemiology: Beyond the Basics, Jones and Bartlett: Boston, 2007 P.315
- 感度 (Sensitivity): 検査法が疾患を正しく検出する能力を評価します。感度は、疾患の存在する人々のうち、検査で陽性と判定された割合を示します。
- 特異度 (Specificity): 検査法が健康な人々を正しく陰性と判定する能力を評価します。特異度は、健康な人々のうち、検査で陰性と判定された割合を示します。
- Youden指数 (J): Youden指数は、感度と特異度のバランスを示す指標です。Youden指数は、感度と特異度の和から1を引いた値で計算されます。Youden指数が高いほど、検査法の性能が良いことを意味します。
- 一致率 (Percent Agreement): 現行のゴールドスタンダードと新しい検査法の結果が一致する割合を示します。一致率は、両者の結果が同じと判定された割合です。
このコードでは、epibasixパッケージを使用して、与えられたデータセットから感度、特異度、Youden指数、および一致率を計算しています。具体的な計算式は、参考文献で確認できます1。
このような指標を使用することで、新しい検査法の有効性を評価し、疫学研究において適切な判断を行うことができます。
sensSpec関数の実行結果
> summary(sensSpec(dat))
Detailed Sensitivity and Specitivity Output
Input Matrix:
Gold Standard A Gold Standard B
Reported A 18 19
Reported B 1 11
The sample sensitivity is: 94.7%
95% Confidence Limits for true sensitivity are: [84.7, 104.8]
The sample of specificity is: 36.7%
95% Confidence Limits for true specificity are: [19.4, 53.9]
The sample value of Youden's J is: 31.4
95% Confidence Limits for Youden's J are: [11.4, 51.4]
Sample value for Percent Agreement (PA) is: 59.2%
95% Confidence Limits for PA are: [45.4, 72.9]
ま、そういう事みたいです。
univar関数
このRコードは、単一の変数に対する詳細な単変量解析を提供します。具体的には、以下の統計量を計算します:
- 平均 (mean): 観測値の平均値。
- 中央値 (median): 観測値の中央値。
- 標準偏差 (standard deviation): 観測値のばらつきの尺度。
- 範囲 (range): 観測値の最小値から最大値までの幅。
- 仮説検定と信頼区間のツール。
具体的な使用方法は次の通りです:
#This function provides detailed univariate analysis for a single variable. Values include the sample # mean, median, standard deviation and range, as well as tools for hypothesis tests and confidence # intervals. x <- rexp(100) univar(x) # Casella G and Berger RL. Statistical Inference (2nd Ed.) Duxbury: New York, 2002.
univar関数の実行結果
> x <- rexp(100) > univar(x) Univariate Summary Sample Size: 100 Sample Mean: 0.972 Sample Median: 0.632 Sample Standard Deviation: 0.986
ま、このパッケージは他のものでカバーできそうかな