
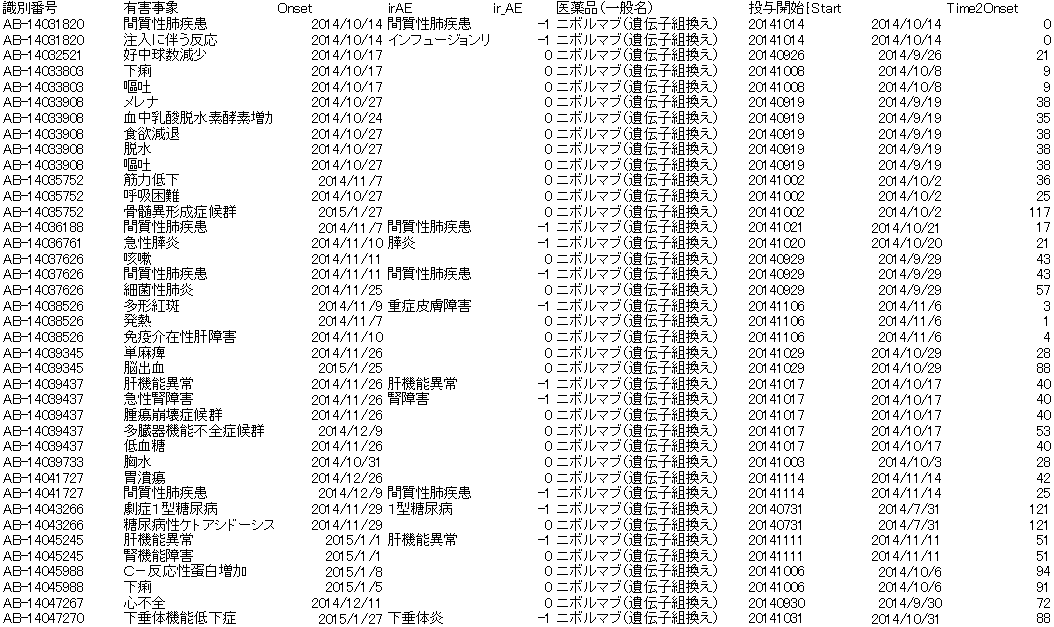
上のようなデータがあったとして、dplyrで少し成形します
- filter() … 行の選択
- arrange() … 行の並び替え
- select() … 指定した列のみ選択
- mutate() … 新しい列の追加
- group_by() … グルーピング
- summarize() … 集計
tidyverse のフィルターを使って
library(tidyverse)
library(readxl)
library(dplyr)
df <- read_xlsx("0050 irAE.xlsx")
df %>%
filter(ir_AE == -1) %>% # ir_AE が-1(TRUEを-1で入力してある)の行のみ選択
arrange(Time2Onset) %>% # Time2Onsetの順に並べ替え(この後平均を取るので意味なし😛)
group_by(`医薬品(一般名)`, irAE ) %>% # 医薬品およびirAEごとにグループ化
summarise(avTO = mean(Time2Onset)) -> newDF # 医薬品・irAE毎のTime2Onset平均値を計算して、newDFというデータフレームへ書き出す
以下のような出力になりました
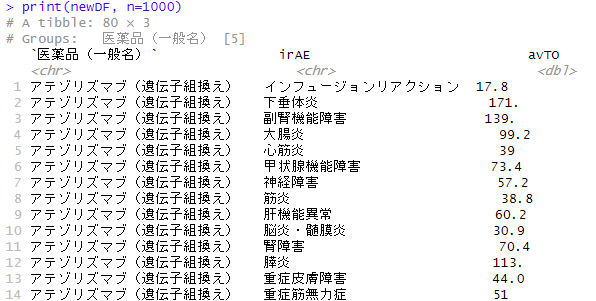
解説
このRスクリプトは、指定されたExcelファイルからデータを読み込み、特定の条件に基づいてデータをフィルタリング、並べ替え、グループ化し、平均値を計算します。
まず、”tidyverse”と”readxl”、”dplyr”という3つのRパッケージを読み込みます。
次に、read_xlsx関数を使用して、指定されたExcelファイル(“0050 irAE.xlsx”)からデータを読み込み、dfという名前のデータフレームに格納します。
その後、dfデータフレームを使用して、ir_AE列が-1(TRUEを-1で入力してある)の行のみを選択します。さらに、Time2Onset列の値を基準に昇順に並べ替えます(ただし、この後の平均値の計算には影響しません)。
次に、医薬品(一般名)とirAEの値を基準にグループ化し、それぞれのグループごとにTime2Onsetの平均値を計算します。計算結果は、”医薬品(一般名)”と”irAE”、”avTO”という列名を持つ新しいデータフレームnewDFに格納されます。
以上が、このRスクリプトの動作です。