
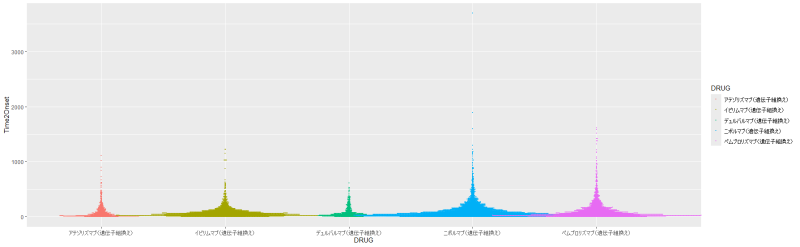
下図のようなdata frame (df.LineList)があります。【ir_AE】というカラムは、 -1 の場合irAE、0の場合非irAEという情報です。
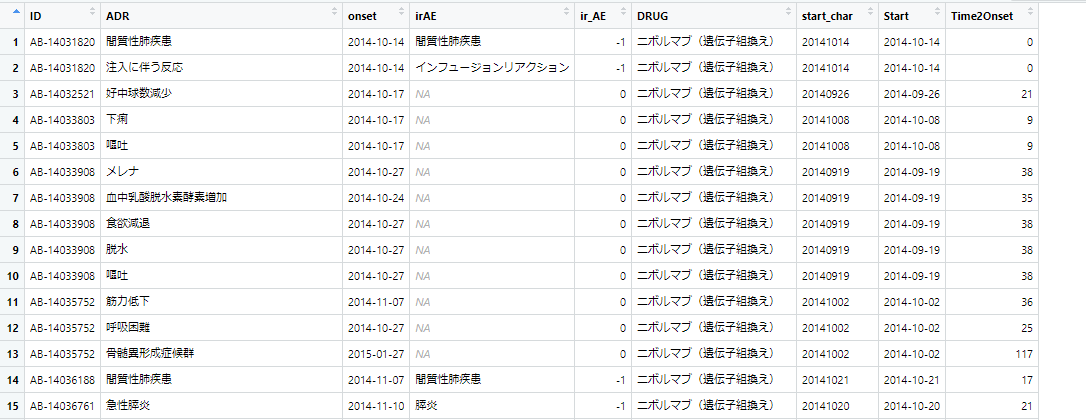
このir_AEカラムを見ながらirAEかどうかの情報を”IRAE”か”nonIRAE”かという文字列を持つカラム【IFirAE】へ書き込みたいという場合のスクリプト。dplyrパッケージのmutate if_else を使います。
library(dplyr) df.LineList <- mutate(df.LineList, IFirAE = if_else(ir_AE == -1, true = "IRAE", false = "nonIRAE"))
実行すると次のようになります。(右端のIFirAE列が追加されている)
一般化したら次のようになります。(マニュアル)
if_else(condition, true, false, missing = NULL, ..., ptype = NULL, size = NULL)
condition
論理ベクトル
true, false
条件の TRUE および FALSE 値に使用するベクトル。 true と false の両方が条件のサイズにリサイクルされます。 true、false、および missing (使用されている場合) は、共通の型にキャストされます。
missing
NULL でない場合は、条件の NA 値の値として使用されます。 true と false と同じサイズと型の規則に従います。
…
これらのドットは将来の拡張用であり、空にする必要があります。
ptype
必要な出力タイプを宣言するオプションのプロトタイプ。 指定した場合、これは true、false、および missing の共通タイプをオーバーライドします。
size
希望の出力サイズを宣言するオプションのサイズ。 指定した場合、これは条件のサイズをオーバーライドします。
Value
条件と同じサイズ、および true、false、および missing の共通型と同じ型を持つベクトル。
条件が TRUE の場合は true の一致値、FALSE の場合は false の一致値、NA の場合は欠落値の一致値 (指定されている場合)、それ以外の場合は欠落値が使用されます。
感想
SQLならチョイとできるデータの扱いもRだと不慣れで調べながらになるのがもどかしい。もちろんSQLとRを行ったり来たりすればいいのでしょうが、チョイと手間がかかるのと、Rのデータをデータベースへ読み込ませ、それをSQLで加工して、データベースからデータを吐き出して、Rへ読み込ませるというのは、ゴミが入る危険性をはらんでいるのでできれば避けたい作業なのです。
library(sqldf)
df_LineList <- df.LineList
df.new <- sqldf('SELECT *, case
when ir_AE == -1 then "IRAE"
when ir_AE == 0 then "nonIRAE"
else ""
end as IFirAE FROM df_LineList')
(でも、Rのsqldfでやろうとすると、case文の文法が私の馴染んでいるやつと結構違う!
1件のコメント