
前回のおはなし
1. SCCSを再び
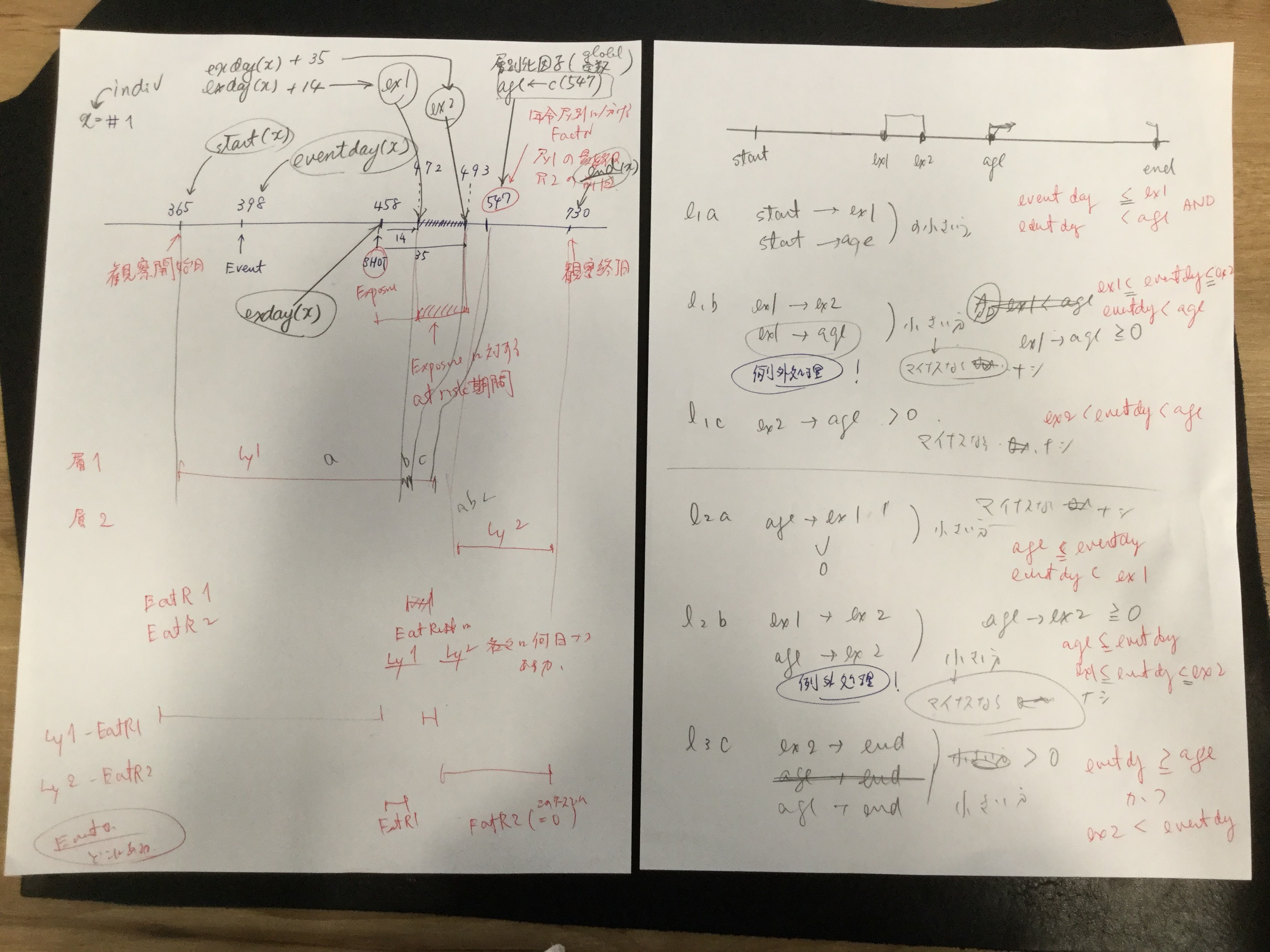
SCCSを自分なりにもう一度噛み砕いて計算の流れを納得した上で、それが間違っていないことを確認したいというのが目的再び挑戦です。前回使用した他人さまの書いたプログラムを参考に、計算の細かい考え方がわかったところで、もう一度どういう計算が必要かを考えています。始めは写真のような、手書きのスケッチで考え方を整理。
2.R→SQL
他人様の書いたRスクリプトを、SQLで表現しなおして、中間テーブルのデータを比較。結果を出力すると、正しいスクリプトだと38行になるところが、今回作成したスクリプトでは39行に?観察期間外にワクチンが接種された患者さんがいることを考慮した例外処理を含め忘れていました。
そんなこんなで、例外処理をするスクリプトを加えた結果が次の写真です。logの有効桁数が違うけどそれ以外内容は同じになりました。

3. 中間テーブルは一致したが…
上の通り、中間テーブルは一致しましたが、オッズ比が一致しません…そんな馬鹿な?しかも、だいたい同じくらいになるんだけど、微妙に不一致。
自分の集計結果:

論文の集計結果:
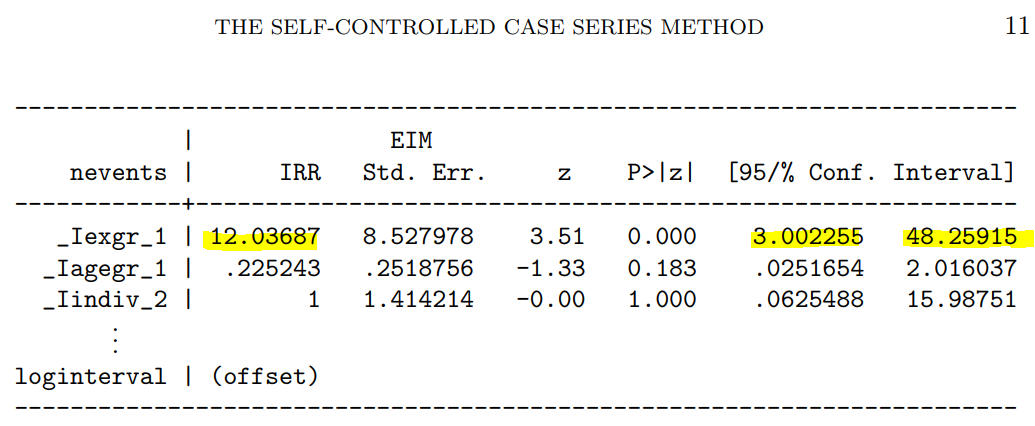
4.桁数が減っている???
いろいろ調べていると、SQL出力をcsvファイルにして、それをRに取り込んだところでデータの桁数(小数点以下)が減っています。元々小数点以下6桁あったはずなのに、2ケタに丸められています。何でこういうことになるのでしょうか? 読み込むRのread.csv関数の設定か? はたまた、読み込んだ後にdata.frameにするところで、宣言しなくてはいけないのか?

5. SQLの集計の出力がおかしい
結局読み取り側の問題ではなく、書き出しに問題ありでした。書き出しの際には、Windowsのコントロールパネルの言語設定のところから桁数を2 -> 6 と大きくすることが必要だということです。

6. めでたしめでたし
ちゃんとSQLのデータを吐き出すことに成功し、読み取って計算すると、論文のデータと一致しました。だいぶ理解が深まってきたぞ。

スクリプトはこちら
このコントロールパネル、windowsのversion upに伴いどこかに行ってしまいました。どこかと言うと、
・ control panel – 地域 – 形式タブ – 追加の設定 – 数値タブ
にありました(2024/05/22 windows 10)