
はじめに
本稿はRのパッケージでdeep learningができると聞いて、ネットで調べながら、パッケージを使う道筋をつけるまでの、忘備録です。サンプルにしたのは、「A薬」で検索した結果と「B薬」で検索した結果を、テキスト形式でA.txt, B.txtとしてPCに保存したうえで、一部を学習用サンプル、残りをテスト用サンプルにして、学習の効果(?)を測定しました。集計に入る前に、ダウンロードしたデータの中の、検索キーワードを削除しました。(←これをしないとさすがに検索キーワードそのものがそれぞれの集団にばっちり入ってしまうので分類の性能が評価できないのではないかと)
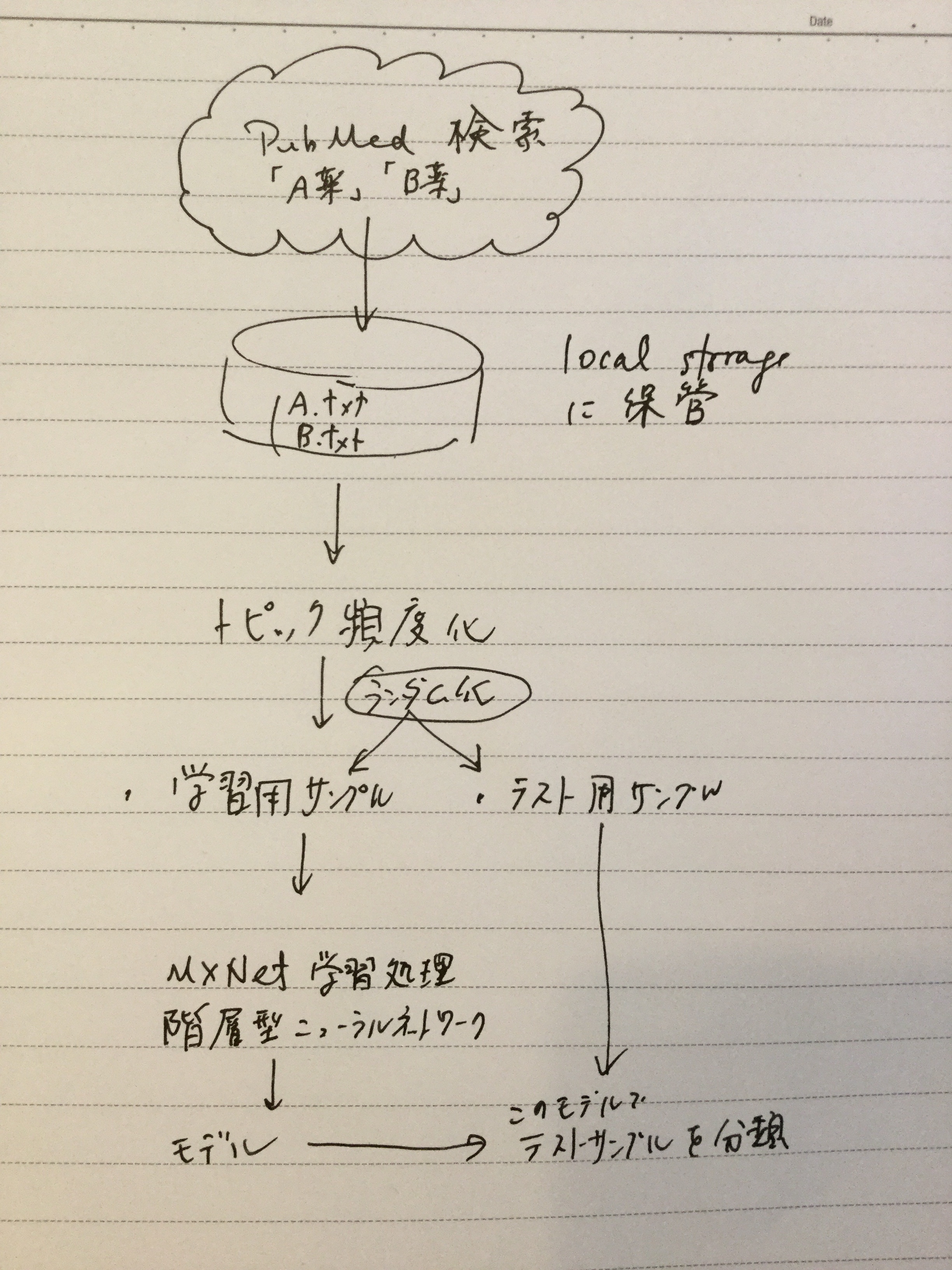
はっきり分類しやすいように、今回はAは抗癌薬、Bは免疫神経系疾患治療薬と治療対象の疾患の性質が違うものにしています。検索結果は、Medline形式でダウンロードします。このあたりの手順は、【Rで自然言語処理】を、ほぼそのまま利用しています。(「データ分析系男子」さんありがとうございます。)分類に使用したMXNetの周りのスクリプトは【RのMXNetでirisを分類】を、ほぼそのまま利用しています(「なんとなくなDeveloper」さんありがとうございます。)
{mxnet}パッケージのインストール
とりあえずこのパッケージのインストールです。インストール方法は、他の日本語のサイトの説明通りでは、なぜかうまくゆきません。一応以下の流れでインストールできました。他のパッケージは特に苦労することなくinstall.packages()でインストールできました。
# first add the repo
drat::addRepo(“dmlc”)
# either install just one or more given packages
install.packages(“xgboost”)cran <- getOption(“repos”)
cran[“dmlc”] <- “https://s3-us-west-2.amazonaws.com/apache-mxnet/R/CRAN/”
options(repos = cran)
install.packages(“mxnet”)
MedLine検索と保管
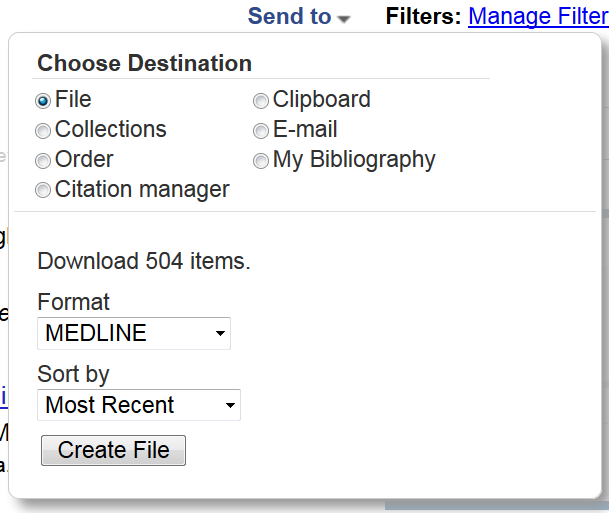
検索キーワードは普通に入力して検索すればよいのですが、あまりたくさんの文献があっても取り回しが悪いので今回は検索対象を今年出版の文献としました。またアブストラクトで分類しますので、アブストラクトが入力されている英語の文献に絞って出力するようにしました。
保存に当たっては、send toからFile-Medline形式を選択しました。
Medline読み込み
setwd(“C:/Users/Oshima/Documents/2018/R deep learning/TXT/”)
## define function
medline <- function(file_name){
lines <- readLines(file_name)
medline_records <- list()
key <- 0
record <- 0
for(line in lines){
header <- sub(” {1,20}”, “”, substring(line, 1, 4))
value <- sub(“^.{6}”, “”, line)
if(header == “” & value == “”){
next
}
else if(header == “PMID”){
record = record + 1
medline_records[[record]] <- list()
medline_records[[record]][header] <- value
}
else if(header == “” & value != “”){
medline_records[[record]][key] <- paste(medline_records[[record]][key], value)
}
else{
key <- header
if(is.null(medline_records[[record]][key][[1]])){
medline_records[[record]][key] <- value
}
else {
medline_records[[record]][key] <- paste(medline_records[[record]][key], value, sep=”;”)
}
}
}
return(medline_records)
}## read Medline
fileVec <- list.files(file.path(getwd()),
pattern=”.txt”,
full.names = T)
categoryVec <- list.files(file.path(getwd()),
pattern=”.txt”)
dataMed <- lapply(fileVec,medline)## exstract Title, Abstract and CategoryVec
dataMedList <- lapply(seq(1,length(dataMed)),function(x){
res <- lapply(seq(1,length(dataMed[[x]])),function(y){
out <- data.frame(title=dataMed[[x]][[y]]$TI,
abst=dataMed[[x]][[y]]$AB,
category=categoryVec[x])
return(out)
# return(x)
})
return(do.call(rbind,res))
# return(y)
})dataMedDF <- do.call(rbind,dataMedList)
データの前処理
dataMH <- sapply(dataMed,function(i){
sapply(i,function(x){
if(all(!(names(x) %in% “MH”))){
strMH <- c()
}else{
strMH <- strsplit(x$MH,”;”)
}
strMHgsub <- gsub(” “,”_”,strMH[[1]])
strMHpaste <- paste(strMHgsub,collapse = ” “)
return(strMHpaste)
})
})
トピック頻度のデータフレームを作成しました。ここでは、上述のサイトに倣ってk=20でやっています。
library(textmineR)
library(text2vec)
library(tm)
library(topicmodels)# create vector of abstracts
allTexts <- sapply(dataMed,function(i){
sapply(i,function(x){
ti <- gsub(“\\[|\\]”,””,x$TI)
if(all(!(names(x) %in% “MH”))){
strMH <- c()
}else{
strMH <- strsplit(x$MH,”;”)
}
strMHgsub <- gsub(” “,”_”,strMH[[1]])
strMHpaste <- paste(strMHgsub,collapse = ” “)
paste(ti,x$AB,strMHpaste,collapse=” “)
})
})allTexts <- unlist(allTexts)
# preprocess
sw <- c(“i”, “me”, “my”, “myself”, “we”, “our”, “ours”,
“ourselves”, “you”, “your”, “yours”, tm:::stopwords(“English”))
preText <- tolower(allTexts)
preText <- tm::removePunctuation(preText)
preText <- tm::removeWords(preText,sw)
preText <- tm::removeNumbers(preText)
preText <- tm::stemDocument(preText, language = “english”)# tokenize(split into single words)
it <- itoken(preText,
preprocess_function = tolower,
tokenizer = word_tokenizer)
#, ids = abstID)# delete stopwords and build vocablary
vocab <- create_vocabulary(it,
stopwords = sw)# word vectorize
vectorizer <- vocab_vectorizer(vocab)# create DTM
dtm <- create_dtm(it, vectorizer)
# Term frecency
TDF <- TermDocFreq(dtm)# modeling by package “topicmodels”
model <- LDA(dtm, control=list(seed=37464847),k = 20, method = “Gibbs”)termsDF <- get_terms(model,100)
topicProbability <- data.frame(model@gamma,dataMedDF$category)
今回は学習用サンプルを80%, 評価用サンプルを20%にして、分けました。
train_size <- 0.8
n <- nrow(topicProbability)
perm <- sample(n, size=round(n * train_size))# data for training
train <- topicProbability[perm, ]# data for test
test <- topicProbability[-perm, ]# imput data for training
train.x <- data.matrix(train[1:20])# label for training
train.y <- as.numeric(train$dataMedDF.category) -1# imput data for test
test.x <- data.matrix(test[1:20])# label for test
test.y <- as.numeric(test$dataMedDF.category) -1
以上データの前処理でした。
階層型ニューラルネットワーク
データの前処理が終わりましたので、ここからがいわゆる機械学習の処理になります。iris記事に倣って、本稿でも次のようにしています。
| 引数 | 備考 | 今回のパラメータ |
|---|---|---|
| hidden_node | 隠れ層のノード(ニューロン)数 デフォルトは1 | 5 |
| out_node | 出力ノード数(分類数、今回はA薬とB薬の2) | 2 |
| num.round | 繰り返し回数(デフォルトは10) | 100 |
| array.batch.size | バッチサイズ(デフォルトは128) | 10 |
| learning.rate | 学習係数 | 0.1 |
| activation | 活性化係数(デフォルトは'tanh') | 'relu' |
‘tanh’, ‘relu’とはなんぞや、というのは解らない。「フリーランスのプログラマ」さんによると、「結論から言うとReluを使おう」なのだそうです。
# deep learning
library(mxnet)
mx.set.seed(0)# 学習
model <- mx.mlp(train.x, train.y,
hidden_node = 5,
out_node = 2,
num.round = 100,
learning.rate = 0.1,
array.batch.size = 10,
activation = ‘relu’,
array.layout = ‘rowmajor’,
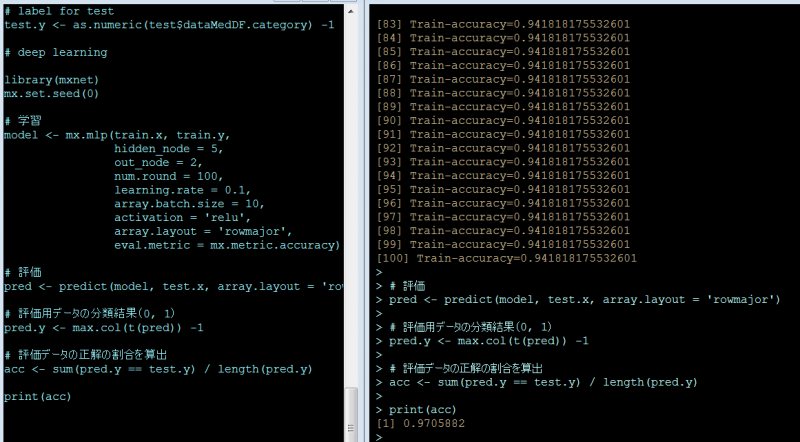
eval.metric = mx.metric.accuracy)# 評価
pred <- predict(model, test.x, array.layout = ‘rowmajor’)# 評価用データの分類結果(0, 1)
pred.y <- max.col(t(pred)) -1# 評価データの正解の割合を算出
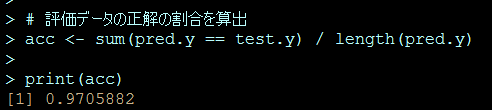
acc <- sum(pred.y == test.y) / length(pred.y)print(acc)
結果
次の通り97.1% (95%CI; 92.6 – 99.2) の割合で正解に分類できました。
10/4/2019時点でbioconcuctorがR3.6.0に対応ということですが、R3.6.1ではインストールできませんでした。3.6.0バージョンのRは次のアドレスにありました。
https://cran.r-project.org/bin/windows/base/old/3.6.0/
Bioconductor のインストールも元記事の通りでは機能せず次で
if (!requireNamespace(“BiocManager”, quietly = TRUE))
install.packages(“BiocManager”)
BiocManager::install()