http://annals.org/aim/fullarticle/2686004/venous-leg-ulcers-japanese-version
私がかかわっているプロジェクトの成果第2弾がAnnals of Internal Medicine誌のホームページに掲載されました。めでたし。

http://annals.org/aim/fullarticle/2686004/venous-leg-ulcers-japanese-version
私がかかわっているプロジェクトの成果第2弾がAnnals of Internal Medicine誌のホームページに掲載されました。めでたし。
今月は2件のガリプルーフのチェックを行いました。ないときは何か月もないのですが、集中する時は近いタイミングで発生します。2件のうち1件は非常に短い(語数が少ない)ので、確認は楽勝でしたが、もう1件は、自分自身が非専門領域の専門誌で、全体で3000語弱の英文のフルペーパーでしたので神経を使います。このジャーナルはaccept前のレビューも若干長めで時間がかかっていましたし、レビューワーのコメントもデータの解釈の方向や議論の主張の仕方など細かい指示が多かったように思います。一方、多くのジャーナルで指摘される「英語が読みにくい」「専門の英文校閲会社を利用しなさい」といった指摘はありませんでした。私が急に英作文が上手くなったはずはなく、その専門領域の先生方の特性を反映しているものではないかと思います。
今回イラついたのは、出版社が組版に際して手を加えてきたことでした。a や theを入れ替えたり、文法が間違ったりしているのを修正すると言うのは他の出版社でもあります。しかし、今回は1つのテーブルを2つに分割して、新たにテーブル番号を振ってきました。テーブルは本文で参照する際に紐付しているのですが、紐付が間違っていて、本文中で参照するテーブル番号が当初意図していたのとは別のテーブルを指しています。これを修正するのは神経を使います。そして、出来上がってみたら、参照する順に番号が1, 2, 5, 3, 4になって、途中で参照するTable 5が最後のページに来るといった仕上がりになります。間違って紐付するよりはましだけど、なんか不愉快な感じです。
2018年6月はじめに、京都大学で開催されました米国内科学会日本支部年次総会の役員会で、黒川清先生が安楽死について語っておられました。これだけ高齢化が進むことが何十年も前から予測されながら各時代の政権が実質的な手を打たずに、不作為を続けてきてしまった、というご認識でいらっしゃるようで、声を上げておられるという事でした。安楽死と高齢化? これを結びつけたロジックが解りませんでしたが、年をとったら(健康であっても?)自分で死を選ぶオプションを想定しているのであれば、SFの世界の様な話です。何か見解があれば、ご自身のブログにコメントを寄せてほしい、と言う事でしたのでそのブログを見に行きました。
まず、ブログを見て圧倒されたのが文字数の多さです。一通りザーッと流し読みするにも小一時間。そして、このテーマを「医学生のお勉強」として取り上げておられることもびっくりしました。安楽死にまつわる周辺の様々なことについて議論されています。雑談の様に雑多な話題から周辺の情報もちゃんぽんの様に入っている。議論として積みあがるというよりは、周辺ばかり。そう、話題の「安楽死とは」どういうものを言うのか、定義していない。何について議論しているのか、共通の認識を確認しないまま進んでいるのでなにか落ち着かないのです。
なぜ定義にこだわるのでしょうか。それなしでは、何を議論してどこに落ち着こうとするのかが見えないからです。いろいろな定義があってしかるべきですが、少なくとも「自分たちが、今議論しているものはこういうものだ」というのを確認する必要はあります。
自分が死にたいと思って死を選ぶ、「安楽死」-「尊厳死」-「自殺」 何が違ってどこに境界線があるか、整理できてますか? 国内では「安楽死」は過去に裁判を通して司法が4要件(6要件)を示して整理してくれています。4要件を少し緩めた物が「尊厳死」ですが、海外では日本の「安楽死」の要件を緩めて「安楽死」の様に扱っている様でもあります。「尊厳死」と「自殺」は、一般の人が思い浮かべるようなイメージでは明確に分かれていると思いますが、性質としては非常に近くて線引きは難しいものです。そこに至る社会的な背景が違うだけのようにも思います。安楽死を選ぶ権利を許容するが、自殺は許容しない、といった具合に真逆な判断をするためには、その2者の間に明確な線を引くことが必要になります。
とりあえず、東海大学安楽死事件の判決文を張っておきます。4要件が書かれています。(つづく)

2018年6月はじめに学会で京都に行きました。今回は学会前日の理事会から始まって、最終日最後のプログラムのビジネスミーティングまでいたので週末ずっと京都にいました。理事会は金曜日午後ということで、出席するために会社の方は有休を取りました。そして、少し早めに行って観光をしました。場所は嵐山付近を散策しました。立派なお寺を一つ観て、「これはかつて我が家の定番カレンダーだった、シオノギ卓上カレンダーか国鉄壁掛けで絶対に観たことがある」と思える景色を観てきました。その、普通の感じのやつはいいとして、そのカレンダー寺の付近で気になるオブジェを見つけました。
まず、このネーミングにひっかかりました。「魚雷観音」平和なイメージの観音様と戦争なイメージの魚雷、このミスマッチな組み合わせが、他のオブジェとは何か惹きつけるものを持っていました。
この魚雷は、インプットしたスクリュー音を追尾する仕組みでもなく、あらかじめプログラムされた航路を進む仕組みでもなく、人がマイクロプロセッサ代わりに搭載されていたそうです。
作戦に関わった多くの方が亡くなっていますので、その方々を慰める観音様ということだろうと思います。
インパクトの大きな医学研究で使用した統計ソフトのコードを公開するべきだという論評
Assel M, Vickers AJ. Statistical Code for Clinical Research Papers in a High-Impact Specialist Medical Journal. Ann Intern Med. 2018;168:832–833. doi: 10.7326/M17-2863
<原文は自前のデータを提示してはいますが、ほぼ、思うところを述べている論評です>
1. 定量的医学研究・
First, software practices and principles should become a core part of biostatistics curricula, regardless of the degree (under- or postgraduate) or subject (biostatistics, public health, or epidemiology). Given that students will have to write code when they perform analyses as practicing investigators, we question why so few degree programs in quantitative medical science teach good coding practice.
2. 教室内で、統計解析のコードをピアレビューすべきだというが、
Second, statistical code should undergo intramural peer review. Colleagues should routinely share code to receive constructive criticism just as they share drafts of scientific papers.
3. 自分自身が「エレガント」だと思うような綺麗なコードは、
Finally, code associated with published research should be archived. Doing so would not only improve transparency and reproducibility but also help to ensure that investigators write better-quality code…. We believe well-written code has more than cosmetic value and that dirty code may lead to scientific errors.
「We urge the medical research community to take immediate remedial action」:
# ちなみに、この論評で推進を論じているcode share、「格安航空会社のホームページでチケットを予約したのに、空港で待っていたのは国内大手の機材だった」感じです。
2018/4/27(FRI) @ Casa Classica
ぱんだウインドオーケストラのトランペットパートメンバーによるアンサンブルSEEDのライブに行ってきました。出演されたのは、笠原日向さん・片野和泉さん・佐藤玲伊奈さん・重井吉彦さん・中村諒さんの5名。会場には若い方が多かった中、舞台目の前に陣取ったテーブルに私と、メンバーの片野さんのお母さんが世代が上で保護者席の様な感じになっていました。そこまで広くない会場で、トランペット5本が目の前で鳴ると音圧がすごい迫力でした。中村さんの相変わらずの安定した音は聴いていて安心できます。笠原さん、通常は耳に突き刺さるようなハイノートを楽しませてくださいますが、この日は「3万円ほどでヤフオクで落札した」というバストランペットにトロンボーンのマウスピースを付けてアンサンブルに入っておられました。みなさんおしゃべりは苦手な様ですが、前半おしゃべりが少なくどんどん進んでいくと少しバテから回復する時間がないのでは、という感じでした。チラシは重井さんがスマホアプリで作成されたものだそうです。
https://drive.google.com/file/d/0B23Rvhh_yGe1SkRMeUtUV2U5a19MdURVSmcyTTIxdnpaXzdz/view?usp=sharing



全体を録画したつもりなのですが、うまく取れていたのは最後の曲だけでした。(失礼)
なお、この楽曲はJASRAC DB上はPublic Domainなのですが、youtubeに掲載しましたところ「Hexacorp (music publishing)」というところが何らかの権利を有していると主張してメールを送ってきました。動画の掲載は継続していてよいが、広告が現れる場合がある(広告収入がHexacorpに入るものと思われます)と言う連絡を受けました。継続して掲載可能という事ですので特に異議を主張していません。将来条件が変わり削除を求められるようなことになりましたら、削除するかもしれませんのであしからず。

 実は、このSabaoというグループ、寡聞にして2018年現在活動を続けておられることすら認識していなかったのですが、今回のライブの数日前にたまたま検索する気になって、このインストアライブを知ることになりました。目的は1999年紅白歌合戦でも披露した「春~spring~」 です。その紅白を見た当時、我が家は私の米国留学中で、数少ない日本からの放送(当時)で聴いた曲です。当時、米国から見て太平洋の向こう側のNHKホールのステージで歌っておられて、文字通り手の届かないような場所にいらっしゃったお二人が、本当に手の届きそうな目の前で曲を演奏しているのを見て感動です。そして、約20年と言う長い年月が経ってますます歌声に磨きがかかっていたのも素敵でした。特にファンという訳でもなかったので、大ヒットしたspring以外の他の曲はよく知らないわけですが、今回のライブで少し聴いてみようかなと言う気になりました。
実は、このSabaoというグループ、寡聞にして2018年現在活動を続けておられることすら認識していなかったのですが、今回のライブの数日前にたまたま検索する気になって、このインストアライブを知ることになりました。目的は1999年紅白歌合戦でも披露した「春~spring~」 です。その紅白を見た当時、我が家は私の米国留学中で、数少ない日本からの放送(当時)で聴いた曲です。当時、米国から見て太平洋の向こう側のNHKホールのステージで歌っておられて、文字通り手の届かないような場所にいらっしゃったお二人が、本当に手の届きそうな目の前で曲を演奏しているのを見て感動です。そして、約20年と言う長い年月が経ってますます歌声に磨きがかかっていたのも素敵でした。特にファンという訳でもなかったので、大ヒットしたspring以外の他の曲はよく知らないわけですが、今回のライブで少し聴いてみようかなと言う気になりました。
ライブ中からサイン会終了までは撮影・録音・録画禁止という事でアナウンスされていました。このページに貼ってある画像や動画は、リハーサルの音出しのと時にほんの少しだけ、録画・撮影しました。じつは音出しの時にはちゃんとバランスよく音が出来上がっていたのに、本番が始まるとボーカルの音がほとんど聞こえません。にもかかわらず、vocalのtamaさんはミキサーに向かって、音量を下げるようにと言う合図を何回も出します。別のスタッフは客席の後ろからミキサーのところまで駆け寄ってきて何か指示しています。2曲目まで終わったところで、解ったのですが、内音はvocalの声量が大きくてバランスが悪かったという事です。で、外音にはvocalが出ていなかったこともステージに伝わりました。結局DJのマイクをvocalが使用することで、残りの2曲は無事バランスよく楽しむことができました。4曲目が目的の「春~Spring~」でした。



Podcast: Play in new window | Download
MacにインストールしたRが古くなり、パッケージが動かない状況も見受けられるので一旦アンインストールして、その上で最新版をインストールしようと思いました。でも、RってApplestoreからインストールしたアプリでないのと、アンインストーラが付属していないので、どうやって削除するのか。まずは下調べです。
<https://cran.r-project.org/doc/manuals/r-release/R-admin.html#Uninstalling-under-macOS>
4.2 Uninstalling under macOS
R for macOS consists of two parts: the GUI (R.APP) and the R framework. The un-installation is as simple as removing those folders (e.g. by dragging them onto the Trash). The typical installation will install the GUI into the /Applications/R.app folder and the R framework into the /Library/Frameworks/R.framework folder. The links to R and Rscript in /usr/local/bin should also be removed.
If you want to get rid of R more completely using a Terminal, simply run:
sudo rm -rf /Library/Frameworks/R.framework /Applications/R.app \
/usr/local/bin/R /usr/local/bin/RscriptThe installation consists of up to four Apple packages:18 org.r-project.R.el-capitan.fw.pkg, org.r-project.R.el-capitan.GUI.pkg, org.r-project.x86_64.tcltk.x11 and org.r-project.x86_64.texinfo. You can use pkgutil –forget if you want the Apple Installer to forget about the package without deleting its files (useful for the R framework when installing multiple R versions in parallel), or after you have deleted the files.
Uninstalling the Tcl/Tk or Texinfo components (which are installed under /usr/local) is not as simple. You can list the files they installed in a Terminal by
pkgutil –files org.r-project.x86_64.tcltk.x11
pkgutil –files org.r-project.x86_64.texinfoThese are paths relative to /, the root of the file system.
上記を自動翻訳するとこんな感じです。
R for macOSは、GUI(R.APP)とRフレームワークの2つの部分で構成されています。アンインストールは、それらのフォルダを削除するだけで簡単です(例えば、ゴミ箱にドラッグするなど)。標準的なインストールでは、GUIは/Applications/R.appフォルダに、Rフレームワークは/Library/Frameworks/R.frameworkフォルダにインストールされます。 / usr / local / binにあるRおよびRscriptへのリンクも削除する必要があります。
> sudo rm -rf /Library/Frameworks/R.framework /Applications/R.app \
/usr/local/bin/R /usr/local/bin/Rscript
rm -rf /
ここに提示されるデータは、治験・市販後の実データを元にしていますが、実際のデータではありません。LearnBayesというRのパッケージはベイズ推計を行えるような関数を提供しています。説明書を読みながら、このパッケージの一部機能を使ってみてみました。
海外の治験のデータがすでにあり、その後国内で試験を行って副作用データが新たに得られた。と言う場合を想定した解析をしてみた。
海外臨床試験では、被験者135例中50例に副作用が報告された。普通の頻度の解析によると副作用が報告される割合は、本剤使用者の37.0% (95%CI; 28.9 – 45.8)となる。
> binom.test(50, 135)
Exact binomial test
data: 50 and 135
number of successes = 50, number of trials = 135, p-value = 0.00328
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.2888945 0.4576672
sample estimates:
probability of success
0.3703704
この計算結果をもとに、β分布を推定する。95%信頼区間の上限(p=0.975)を与えるxの値は0.4576672であり、最尤値(p=0.5)を与えるxの値は0.3703704。この2点を与えれば事前確率のβ分布のパラメータが推定できる。
quantile2 <- list(p=.975, x=.458)
quantile1 <- list(p=0.5, x=.370)
beta_parm <- beta.select(quantile1, quantile2)
a <- beta_parm[1]
b <- beta_parm[2]
国内臨床試験では海外より被験者が少なく、23例が安全性解析対象症例となった。23例中11例で副作用が報告された。この結果と事前推定されているβ分布のパラメータを元に前後の分布を図示する。
# 事後分布
curve(dbeta(x,a+s,b+f), from=0, to=1, xlab=”p”,ylab=”Density”,lty=1,lwd=4)
# 実験結果から出てくるイベント発生頻度の尤度
curve(dbeta(x,s+1,f+1),add=TRUE,lty=2,lwd=4)
# 事前分布
curve(dbeta(x,a,b),add=TRUE,lty=3,lwd=4)
legend(.7,9,c(“Prior”,”Likelihood”,”Posterior”), lty=c(3,2,1),lwd=c(3,3,3))
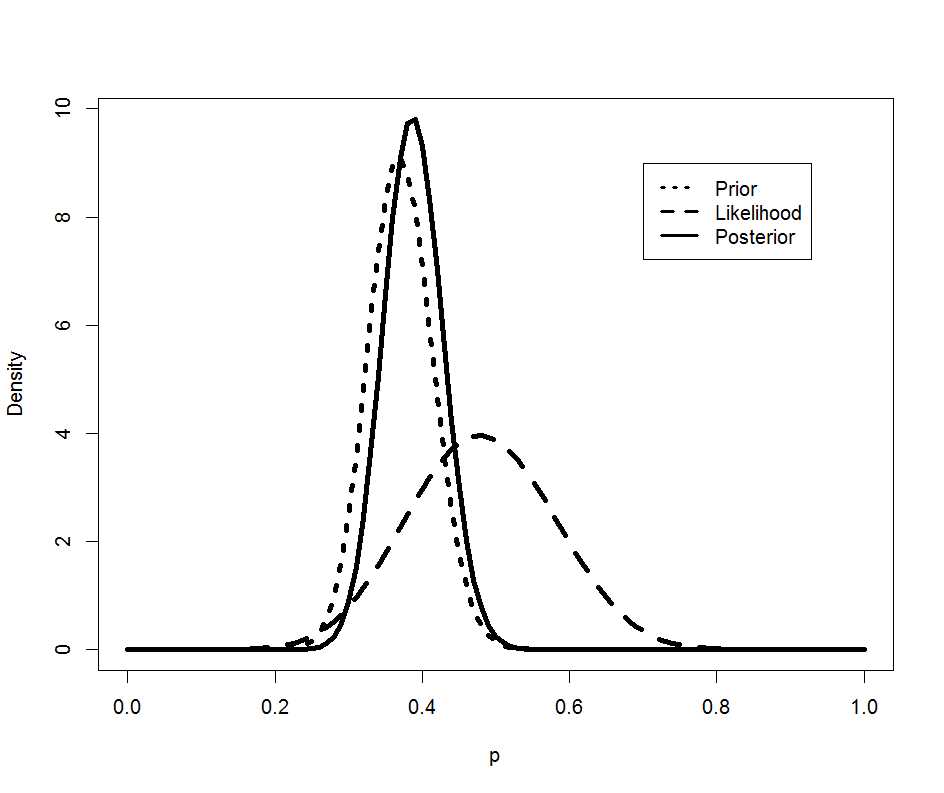
国内試験のデータの分布(荒い破線)のデータが得られた後も、事後の分布(実線)は事前分布(細かい破線)と大きく変わらないようだ。
# 事後の分布による推定
> # 90%信頼区間
> qbeta(c(0.05, 0.95), a+s, b+f)
[1] 0.3222927 0.4550214
> # 点推定
> qbeta(0.5, a+s, b+f)
[1] 0.3872558
事後の確率は0.39 (90%CI; 0.32 – 0.46)で、国内のデータ0.48 (90%CI; 0.30 – 0.66)とずいぶんずれているように見える。
# 国内データのみによる推定
> binom.test(11, 23, conf.level=.9)
Exact binomial test
data: 11 and 23
number of successes = 11, number of trials = 23, p-value = 1
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.2960934 0.6648524
sample estimates:
probability of success
0.4782609
上記の臨床試験の結果を元に承認申請がなされ、製造販売の承認を得た。市販後はこの医薬品は治験に参加した被験者の数よりはるかに多い患者さんに使用されて多くの安全性データを得た。治験の結果を事前分布、市販後のデータを加えて事後の分布を集計してみる。
上記の分布を事前分布の確率密度関数のパラメータ推計に用いる
# 90%信頼区間の上限 0.95のx値は0.455
quantile4 <- list(p=.95, x=.455)
quantile4$x <- qbeta(0.95, a+s, b+f)
# 事前確率(点推定; p=0.5)は0.387であった
quantile3 <- list(p=0.5, x=.387)
quantile3$x <- qbeta(0.5, a+s, b+f)
beta_parm <- beta.select(quantile3, quantile4)
a <- beta_parm[1]
b <- beta_parm[2]
国内の市販後の調査に登録され安全性解析対象とされた患者は2072例であり、そのうち964例に副作用が報告された。この結果と事前推定されているβ分布のパラメータを元に前後の分布を図示する。
s <- 964
f <- 2072-s
# 分布を見てみよう
# 事後分布
curve(dbeta(x,a+s,b+f), from=0, to=1, xlab=”p”,ylab=”Density”,lty=1,lwd=4)
# 実験結果から出てくるイベント発生頻度の尤度
curve(dbeta(x,s+1,f+1),add=TRUE,lty=2,lwd=4)
# 事前分布
curve(dbeta(x,a,b),add=TRUE,lty=3,lwd=4)
legend(.7,35,c(“Prior”,”Likelihood”,”Posterior”), lty=c(3,2,1),lwd=c(3,3,3))
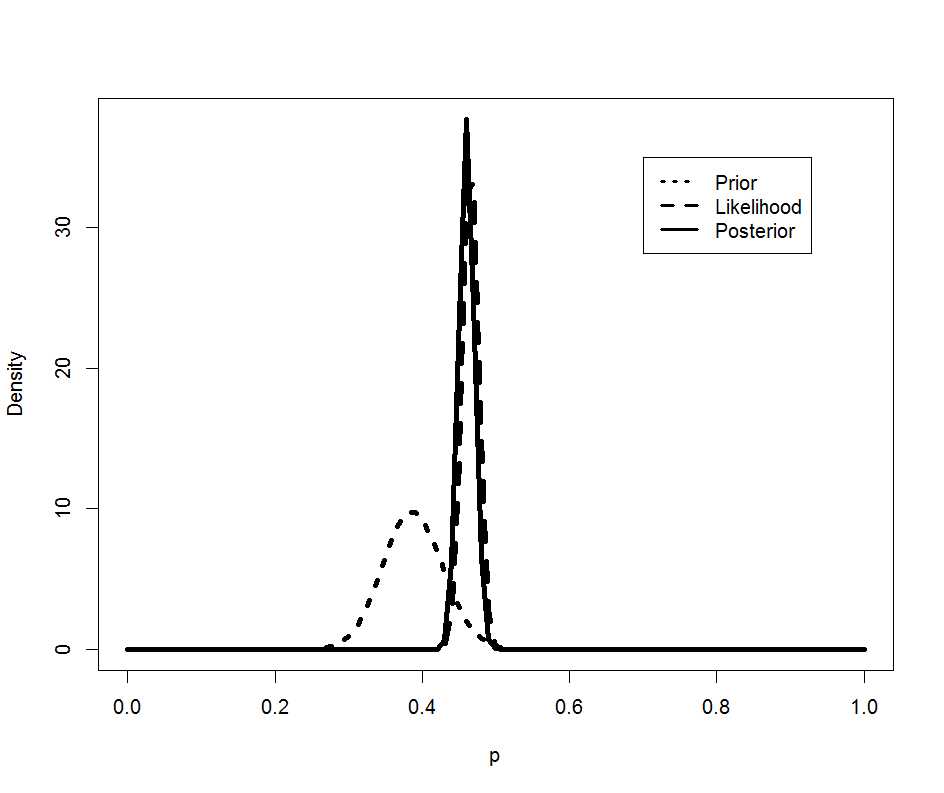
市販後の調査のデータの分布(荒い破線)のデータが得られた後、事後の分布(実線)は事前分布(細かい破線)から大きく右へシフトした。
# 90%信頼区間
> qbeta(c(0.05, 0.95), a+s, b+f)
[1] 0.4427958 0.4776115
> # 点推定
> qbeta(0.5, a+s, b+f)
[1] 0.4601712
図から受ける印象の通り、事後の確率は0.46 (90%CI; 0.44 – 0.48)は、事前のデータ0.39 (90%CI; 0.32 – 0.46)とずれているように見える。実は、事後の確率は、国内治験のデータ0.48 (90%CI; 0.30 – 0.66)を精密にしたように見える。
ここまでやってみた感想
疑問がより具体化したので良しとしよう。
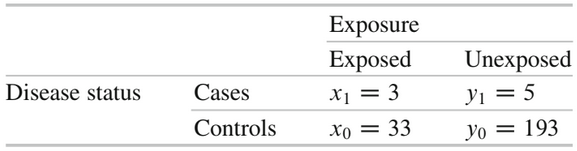
1988年に公開されたSavitzらの論文(症例対象研究)1のデータを触っています。
Caseは白血病症例、Controlはそれ以外の住民。そして、Exposureは閾値を3milligauss (mG)とした場合の居住地での磁気フィールドへの曝露の有無。データは次のようになります。
これを基にβ分布で症例とコントロールの分布の1万例のシュミレーションを行うプログラム。

そして、結果です。
そのヒストグラムを書くと次のように分布します。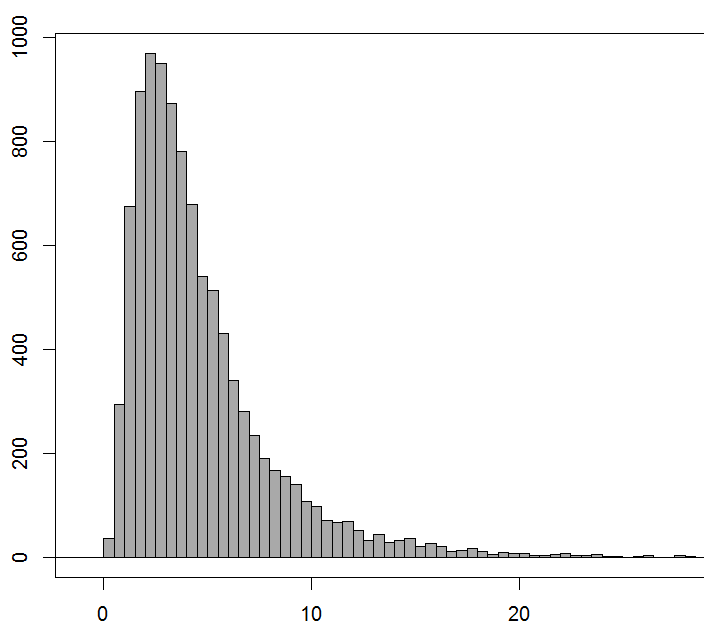
ま、これとは別に普通にFisherのテストをすると次のような結果になっていて、オッズ比は3.48、95%CI 0.51 – 18.89 と幅広い分布をすることが計算できます。



