
12月のデュトワは難しいのかな?

iPodから送信
Who is it?
これは誰かな?
菊池寛美術館?
ここを通りながら菊池寛美術館と読んでいました。書斎の様子が再現してあったり、使っていたペンが展示してあったり、を想像してました。

iPodから送信
Government Shut down
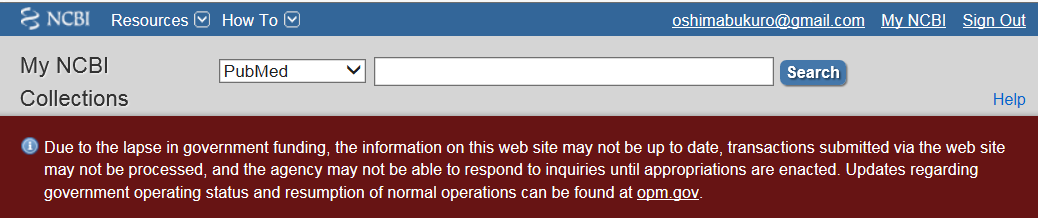 米国で予算の執行が止まっているのを他人事と思っていたけど、影響を受けてしまった
米国で予算の執行が止まっているのを他人事と思っていたけど、影響を受けてしまった
新しい情報が入ってこないとはつらいです。
Snowy morning

雪が積もった朝の、舞浜付近です


Snowy scene
職場からの景色です。愛宕山の神社、NHK放送博物館駐車場が雪景色です。

iPodから送信
Snowy tower
今日は雪が降っていて東京タワーが良く見えません。

iPodから送信

ExProf Asano
2018/01/21 恩師の朝野先生を囲む会に参加しました



iPodから送信
Flugelhorn
今日はフリューゲルホルンを吹いてます。

iPodから送信