
はじめに
ここの所注力してきた仕事が一段落して、この週末は良い具合に一息つけます。
さかのぼること数か月、今後使うかもしれない、自分にとって新しい手法を試しておこうと、 Sequence Symmetry Analysis (SSA)をやってみたんだけど、これがイマイチ。何がイマイチって、製薬工業協会のホームページにSASのプログラムが公開されていて、それを見ながらやっているんだけど細かい数字が合わない。結果はだいたい近いところまでは行くんだけど、何か織り込むべきアイディアが足りないのか。ちなみに、作成にかかわったタスクフォースの方々の名誉のためにもう少し書いておきますと、この公開されているプログラムがおかしいというのではなく、まず、他人の書いたプログラムから、何がなされているのかというのを読み解くのはとても難しい作業で、このプログラムを参考にして、何がされているのかを読み取って、そのうえで自分にとってわかりやすいように書き換えるので、おかしなことが起きているのです。おそらくNull effect sequence ratio, NSRの計算のところがキモなのではないかと思いつつ、しばらくこちらは放置して頭を冷やすことにしていました。。
Self-controlled case series (SCCS)
SCCSとは?
同じself-controlledデザインのSCCSを試してみます。原理はこのスライド2ページ目。当時PMDAで東大epistatの竹内 由則さんが学会発表したスライドからです。

データ
データが公開されているので、手法を試すのにちょうどよいということで、試してみるのは、この文献Whitaker HJ, Farrington CP and Musonda P. Tutorial in Biostatistics: The self-controlled case series method. Statistics in Medicine 2006, 25(10): 1768-1797.に出てくるMMRワクチン後の髄膜炎。Table 2にOxford dataとして提示されています。
| indiv | eventday | start | end | exday |
| 1 | 398 | 365 | 730 | 458 |
| 2 | 413 | 365 | 730 | 392 |
| 3 | 449 | 365 | 730 | 429 |
| 4 | 455 | 365 | 730 | 433 |
| 5 | 472 | 365 | 730 | 432 |
| 6 | 474 | 365 | 730 | 395 |
| 7 | 485 | 365 | 730 | 470 |
| 8 | 524 | 365 | 730 | 496 |
| 9 | 700 | 365 | 730 | 428 |
| 10 | 399 | 365 | 730 | 716 |
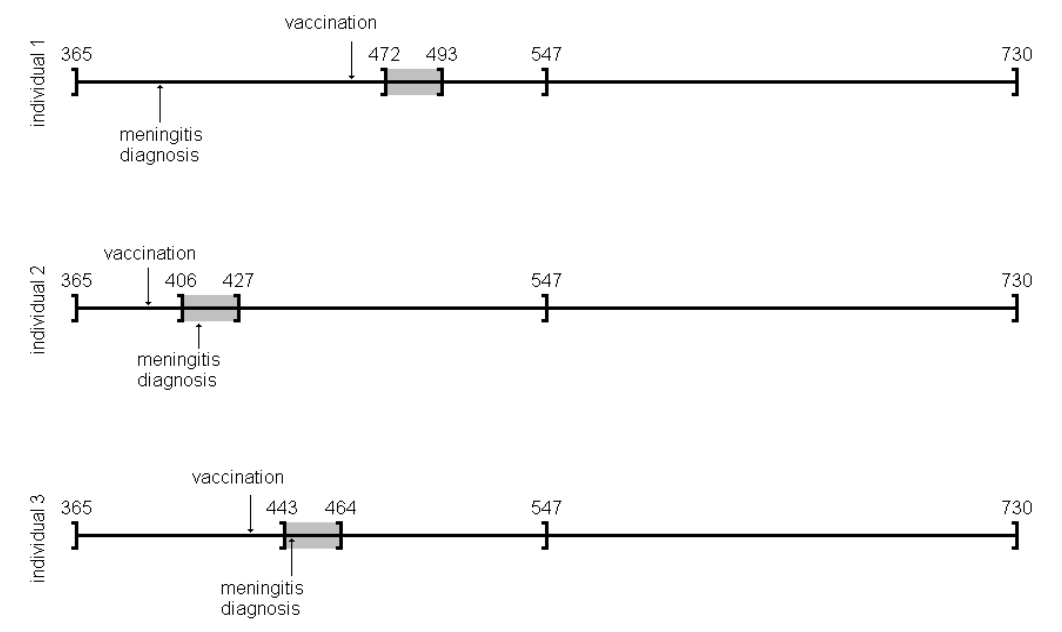
データは10例ですべて。観察したのは、全員生後366日から730日。データのカラムstart, endは観察期間の開始を生後の日数で示しています。 exdayがワクチン接種の日、eventdayが髄膜炎と診断された日、で、これも生後の日数で示しています。
元論文では、at risk 期間をmumps virusのreplicationにかかる期間に基づいて、shotから15 – 35日後と設定しました。(元文献のTable 2では、ワクチン接種日は「pre-riskから14を引いた日」になります。ワクチン接種から14日目までがpre-risk, 15日目からがat-riskという考え方だと思います)ダウンロードしたデータにはワクチン接種日がexdayとして入力されていますので次のようにpre-risk(ex1), risk end (ex2)を計算します。設定したat riskの期間によってはスクリプトを触るべき個所がココということになります。
ex1 <- dat$exday + 14
ex2 <- dat$exday + 35
観察期間中のすべての日を、at riskの期間かどうか正確に分類したいので、ワクチン接種が331 – 715日のワクチン接種歴を要求した(原文)ということです。case #10は、716日にワクチンを接種していますが、潜伏期間が観察期間終了後まで継続しますので、結果として観察期間中にat riskの期間がありません。
データをグラフィカルに提示している図があったので、引用。灰色の期間がat riskの期間。そして、547で線が引いてあるのは、ここで年齢層を分けて調整因子として使用しているので、それを示すつもりで線を入れたのでしょう。(例示として示した図の中には、年齢層をまたぐリスク期間を有している症例が出てこなかったので、何を説明したくて547日で線を入れたのかわかりにくくなっていますが。)366 – 547 を1層、548 – 730を2層にしています。観察期間中にイベントが発生したら、それ以降は観察期間にしないというような操作を通常行いますが、この集計では、そうではありません。全体の観察期間を集計して、イベントがどの期間に発生したかというような思想で集計するようです。
年齢層をプログラムしているのはここです。
age <- c(547)
#age groups
agegr <- cut(cutp, breaks = c(min(dat$start), age, max(dat$end)), labels = FALSE)
agegr <- as.factor(agegr)
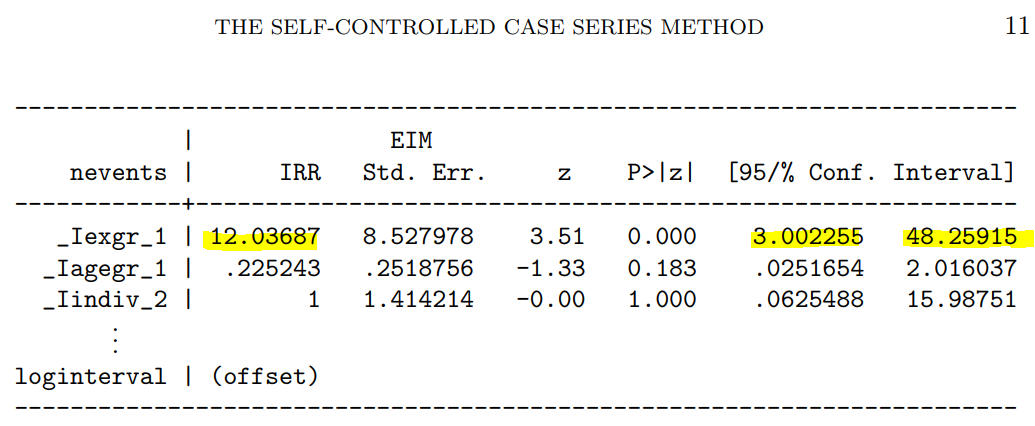
論文の結果
論文の結果が次の通りで、
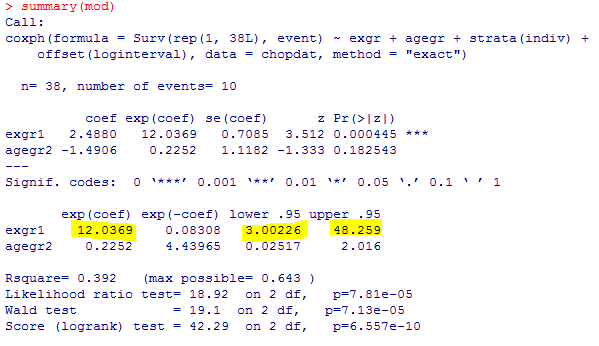
自分でも計算
自分で実行した結果が次。めでたく、結果が一致していました。めでたしめでたし。
おわりに
実行したRのスクリプトがこちら。実行に当たっては私の環境に合うようにOpen Universityのホームページのスクリプトを一部改編しました。実行結果が論文で提示されていたものと一致するので、悪くはないだろうと思います。これでまた、新たな手法を用いたいろいろな評価ができる道筋が付きました。(つづく)
副作用の仕事をしていて学びました。副作用の研究は疫学的なアプローチが不可欠で、疫学的な研究はデータベースのハンドリングが不可欠です。
世の中では「ビッグデータ」とか「リアルワールドデータ」とか言われているものが流行しています。副作用の領域で「ビッグデータ」と言われるものが利用できるのは、データが大きいから何かが言えるようになったというのではありません。むしろ件数の大きなデータは、データ粒度は低く、エラーも多いし、目的に沿ったデータ入力になっていないことが多いです。(二次利用データが多いため)
でも解析方法の研究が進むことで、それらの欠点を克服して利用できるようになってきた、という側面が大きいです。
参考にしたRスクリプトが掲載されていましたサイトの構造が変わっていましたので、あらためてリンクを掲載いたします。
http://stats-www.open.ac.uk/sccs/r.htm