
ケースコントロールスタディのサンプルサイズの見積もり
臨床試験だと、試験に参加する被験者をリクルートするのは骨が折れる仕事ですので、必要最低限の被験者で正確な結果を得たいという欲求は大きく、「サンプルサイズ」の正確な見積もりが求められます。ケースコントロールスタディをする場合も、最終的に元資料を確認したり、新たにデータを入手したりする手間は少ない方が良いので、精密な見積もりが出来た方がベターです。しかし、新たにデータを得ることを想定していないデータベース研究では、サンプルサイズを見積もる要求はどのあたりに発生するでしょうか?データベースをベンダーから購入したり、解析をCROに依頼する際に目的の結果にアプローチできるだけの情報を持っているかどうかを見積もる場合には有用かもしれません。まぁ、流行だということで偉い人からの号令で動いているような多くの人は、何らかの結論にアプローチしたいのではなく「アプローチしている姿勢を見せる」と言う、行動計画ありきで動いているみたいですので、当該ベンダーのデータには、リサーチで明らかにしたい結論に到達できるような、十分なデータが含まれないことが購入前あるいは解析の発注前に明らかになったとして、頭を切り替えるかそのまま突き進むかは目に見えていますが。
それはさておき、単純にケースおよびコントロールでそれぞれ、何人中何人が被疑薬に曝露されていて、そのオッズ比を求めるというようなデザインでのサンプルサイズの求め方がありますので、次の資料のデータをトレースしてみます。
Woodward M (2005). Epidemiology Study Design and Data Analysis. Chapman & Hall/CRC, New York, pp. 381 – 426.
(p. 412) A case-control study of the relationship between smoking and CHD is planned. A sample of men with newly diagnosed CHD will be compared for smoking status with a sample of controls. Assuming an equal number of cases and controls, how many study subject are required to detect an odds ratio of 2.0 with 0.90 power using a two-sided 0.05 test? Previous surveys have shown that around 0.30 of males without CHD are smoker.
事前の見積もりに必要なのは、odds ratio 2.0, power 0.90, two-sided 0.05 testという、研究者が設定するパラメータと、先行研究から得ておくべき背景の情報として「冠動脈疾患にかかっていない男性の30%がスモーカーだ」という、コントロール群の曝露頻度に相当する情報です。あと、コントロールを選ぶ際はマッチングは行わないで、ケースと1:1となる人数にするとしています。ここで設定しているオッズ比は、「オッズ比2.0以上だとリスクとして警告する価値がある」と研究者が思い込むような任意の数字で、基準があるわけではないです。これを、認識しているかどうかで、結果が出た際に(特に差がつかなかった時に)データの解釈の書き方が大きく変わります。
> epi.ccsize(OR = 2.0, p0 = 0.30, n = NA, power = 0.90, r = 1, rho = 0,
+ design = 1, sided.test = 2, conf.level = 0.95, method = “unmatched”,
+ fleiss = FALSE)
$n.total
[1] 376$n.case
[1] 188$n.control
[1] 188
答えは
A total of 376 men need to be sampled: 188 cases and 188 controlsだそうですので、一応、数値は正解です。
「冠動脈疾患にかかっていない男性の30%がスモーカーだ」という先行研究も、よくよく考えると書かれていることがあいまいです。冠動脈疾患にかかっていない男性が将来かからないとは言えないですし。禁煙に成功した人をどう扱っているのか情報もないです。ま、それもさておき、背景の喫煙男性が30%も世の中にいたおかげで、少ないサンプルで研究が成立しそうです。これが、世の中の男子の1%しか使用していない曝露(これが医薬品への曝露なら、世の中の1%の男性が使用しているような薬ならブロックバスターですが)曝露との関係を見ようとすると、次のようになります。
> epi.ccsize(OR = 2.0, p0 = 0.01, n = NA, power = 0.90, r = 1, rho = 0,
+ design = 1, sided.test = 2, conf.level = 0.95, method = “unmatched”,
+ fleiss = FALSE)
$n.total
[1] 6418$n.case
[1] 3209$n.control
[1] 3209
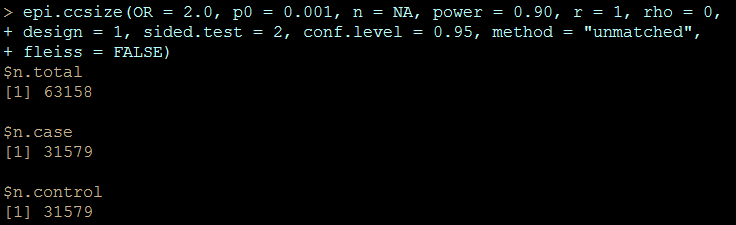
6418例の情報を収集する必要が出てきます。このくらいの数になると、どのようにデータを集めるにしても自前でデータを準備して集計するのは大変そうです。組織だって行動する必要がありそうです。さらに、背景の曝露を0.1%に下げると、次のように6万人超えのサンプルの収集が必要になります。
> epi.ccsize(OR = 2.0, p0 = 0.001, n = NA, power = 0.90, r = 1, rho = 0,
+ design = 1, sided.test = 2, conf.level = 0.95, method = “unmatched”,
+ fleiss = FALSE)
$n.total
[1] 63158$n.case
[1] 31579$n.control
[1] 31579
副作用を研究対象にしていると、このcaseの3万人超えの副作用が出ていないと、結論が出せないように見えます。つまり、副作用の例にあてはめますと、3万人以上の患者さんが副作用になるという、結構な大惨事になってからしかこの方法で結論が出せないという、悲惨な手法です。どこに間違いがあるのでしょうか。おそらくそれは、有名なレンツの研究では結果として上記の例よりかなり大きな数字になっているパラメータでしょう。「オッズ比が20~50になるくらいの本当の強いリスクかどうか」を検証したいという、リサーチクエスチョンを立てるのです。
もう一点できる事やるべき事は、背景での曝露頻度を上げるために、対照集団を絞り込むこともできそうです。結論部分で述べたい一般論との兼ね合いにもなりますが、多くの場合世の中一般の集団からサンプルを得る必要はなく、気になる医薬品が使用されるような特定の基礎疾患にかかっている人の中での曝露でp0を設定すれば、調査対象数を少なく見積もることもできそうです。
Don’t forget to load a library prior to the above-mentioned scrips.
library(epiR)