
RのLearnBayes パッケージで臨床試験と市販後の副作用データを解析してみました
ここに提示されるデータは、治験・市販後の実データを元にしていますが、実際のデータではありません。LearnBayesというRのパッケージはベイズ推計を行えるような関数を提供しています。説明書を読みながら、このパッケージの一部機能を使ってみてみました。
1.海外試験の結果が事前にあって、国内の副作用情報が得られた
海外の治験のデータがすでにあり、その後国内で試験を行って副作用データが新たに得られた。と言う場合を想定した解析をしてみた。
海外臨床試験では、被験者135例中50例に副作用が報告された。普通の頻度の解析によると副作用が報告される割合は、本剤使用者の37.0% (95%CI; 28.9 – 45.8)となる。
> binom.test(50, 135)
Exact binomial test
data: 50 and 135
number of successes = 50, number of trials = 135, p-value = 0.00328
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.2888945 0.4576672
sample estimates:
probability of success
0.3703704
この計算結果をもとに、β分布を推定する。95%信頼区間の上限(p=0.975)を与えるxの値は0.4576672であり、最尤値(p=0.5)を与えるxの値は0.3703704。この2点を与えれば事前確率のβ分布のパラメータが推定できる。
quantile2 <- list(p=.975, x=.458)
quantile1 <- list(p=0.5, x=.370)
beta_parm <- beta.select(quantile1, quantile2)
a <- beta_parm[1]
b <- beta_parm[2]
国内臨床試験では海外より被験者が少なく、23例が安全性解析対象症例となった。23例中11例で副作用が報告された。この結果と事前推定されているβ分布のパラメータを元に前後の分布を図示する。
# 事後分布
curve(dbeta(x,a+s,b+f), from=0, to=1, xlab=”p”,ylab=”Density”,lty=1,lwd=4)
# 実験結果から出てくるイベント発生頻度の尤度
curve(dbeta(x,s+1,f+1),add=TRUE,lty=2,lwd=4)
# 事前分布
curve(dbeta(x,a,b),add=TRUE,lty=3,lwd=4)
legend(.7,9,c(“Prior”,”Likelihood”,”Posterior”), lty=c(3,2,1),lwd=c(3,3,3))
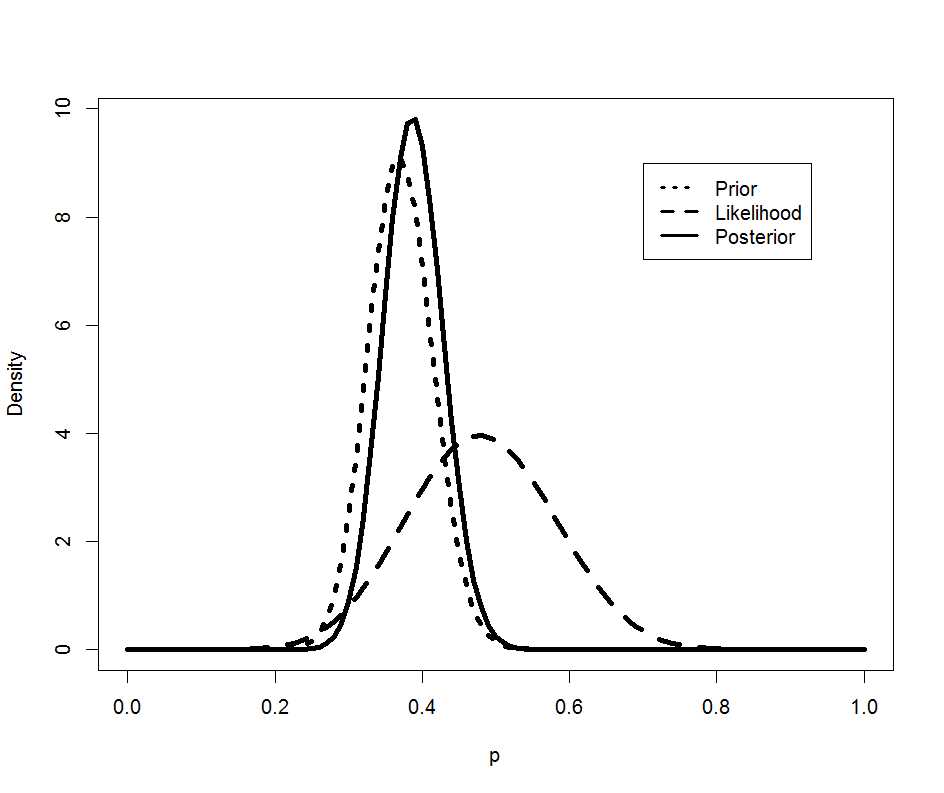
国内試験のデータの分布(荒い破線)のデータが得られた後も、事後の分布(実線)は事前分布(細かい破線)と大きく変わらないようだ。
# 事後の分布による推定
> # 90%信頼区間
> qbeta(c(0.05, 0.95), a+s, b+f)
[1] 0.3222927 0.4550214
> # 点推定
> qbeta(0.5, a+s, b+f)
[1] 0.3872558
事後の確率は0.39 (90%CI; 0.32 – 0.46)で、国内のデータ0.48 (90%CI; 0.30 – 0.66)とずいぶんずれているように見える。
# 国内データのみによる推定
> binom.test(11, 23, conf.level=.9)
Exact binomial test
data: 11 and 23
number of successes = 11, number of trials = 23, p-value = 1
alternative hypothesis: true probability of success is not equal to 0.5
90 percent confidence interval:
0.2960934 0.6648524
sample estimates:
probability of success
0.4782609
2. 治験の結果をもとに製造販売が承認され、市販後に医薬品が使われて安全性データが集積した
上記の臨床試験の結果を元に承認申請がなされ、製造販売の承認を得た。市販後はこの医薬品は治験に参加した被験者の数よりはるかに多い患者さんに使用されて多くの安全性データを得た。治験の結果を事前分布、市販後のデータを加えて事後の分布を集計してみる。
上記の分布を事前分布の確率密度関数のパラメータ推計に用いる
# 90%信頼区間の上限 0.95のx値は0.455
quantile4 <- list(p=.95, x=.455)
quantile4$x <- qbeta(0.95, a+s, b+f)
# 事前確率(点推定; p=0.5)は0.387であった
quantile3 <- list(p=0.5, x=.387)
quantile3$x <- qbeta(0.5, a+s, b+f)
beta_parm <- beta.select(quantile3, quantile4)
a <- beta_parm[1]
b <- beta_parm[2]
国内の市販後の調査に登録され安全性解析対象とされた患者は2072例であり、そのうち964例に副作用が報告された。この結果と事前推定されているβ分布のパラメータを元に前後の分布を図示する。
s <- 964
f <- 2072-s
# 分布を見てみよう
# 事後分布
curve(dbeta(x,a+s,b+f), from=0, to=1, xlab=”p”,ylab=”Density”,lty=1,lwd=4)
# 実験結果から出てくるイベント発生頻度の尤度
curve(dbeta(x,s+1,f+1),add=TRUE,lty=2,lwd=4)
# 事前分布
curve(dbeta(x,a,b),add=TRUE,lty=3,lwd=4)
legend(.7,35,c(“Prior”,”Likelihood”,”Posterior”), lty=c(3,2,1),lwd=c(3,3,3))
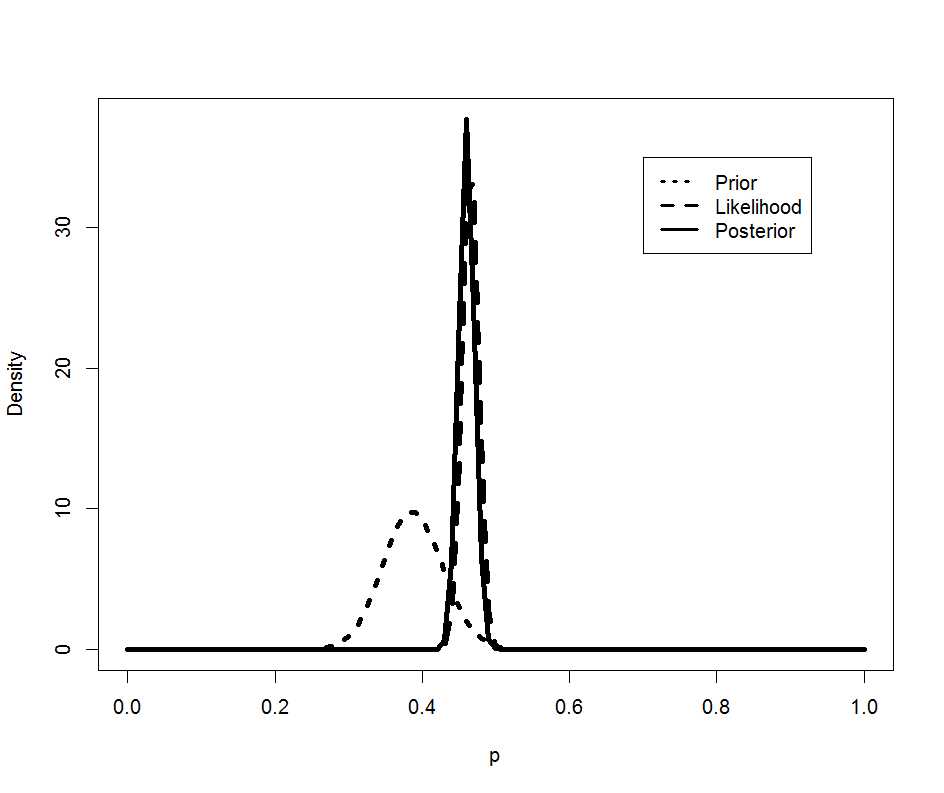
市販後の調査のデータの分布(荒い破線)のデータが得られた後、事後の分布(実線)は事前分布(細かい破線)から大きく右へシフトした。
# 90%信頼区間
> qbeta(c(0.05, 0.95), a+s, b+f)
[1] 0.4427958 0.4776115
> # 点推定
> qbeta(0.5, a+s, b+f)
[1] 0.4601712
図から受ける印象の通り、事後の確率は0.46 (90%CI; 0.44 – 0.48)は、事前のデータ0.39 (90%CI; 0.32 – 0.46)とずれているように見える。実は、事後の確率は、国内治験のデータ0.48 (90%CI; 0.30 – 0.66)を精密にしたように見える。
3. まとめ
ここまでやってみた感想
- 事前の試験・調査と事後とで大きく規模(被験者数)が違う場合、被験者数の大きな方の試験・調査の結果が事後の分布に反映しているだけではないか
- それなら単に規模の大きな試験・調査の結果の分布を集計しても同じではないか、あるいは、単純に足したような併合解析でも結果は似たようなものになるのではないか
- この様な例では、国内外で副作用の報告頻度が異なるという仮説を導きたい
- 結局事後分布って何を示しているものなんだろうか?
- なぜ、β分布を想定するのだろうか?
疑問がより具体化したので良しとしよう。