海外の医学系ニュースサイトで、先週公開された私の論文が紹介されました。
<https://www.medwirenews.com/oncology/non-small-cell-lung-cancer/risks-of-combining-immunotherapy-with-targeted-therapy-radiation/15363470>

海外の医学系ニュースサイトで、先週公開された私の論文が紹介されました。
<https://www.medwirenews.com/oncology/non-small-cell-lung-cancer/risks-of-combining-immunotherapy-with-targeted-therapy-radiation/15363470>
アドレスは次の通り:http://www.ims.u-tokyo.ac.jp/imsut/jp/research/papers/nsclcegfr.php
1/12/2018にTAD wind symphonyコンサートに向かう途中、荻窪駅で出口を間違えて反対側に向かってしまいました。趣のある倉庫のような門があったのでパチリ。表に回ったら「明治天皇御小休所」と書かれていました。


子供のウィンドウズPCに動画編集アプリを入れようとしたところ、Microsoft社のMovie Makerがなぜだか「サポート終了」として、日本の同社のホームページから消えていました。無料であることに加え、ちょっとキャプションを入れるだけの様な簡単な編集には便利なアプリだったので残念、と思っていたら、ダウンロードサイトが他にありました。
<https://www.windows-movie-maker.org/>

JAMA oncology誌に昨年投稿した論文が掲載されました。
リンク先の記事は、救急隊が搬送後に自販機の飲料で一息ついたところが、ある種の大阪市民のお気に召さなかったという内容の様です。 <http://www.city.osaka.lg.jp/seisakukikakushitsu/page/0000419363.html>
九大にいた時消防署に泊まって、救急車の出動時に一緒に救急車に乗って救急の現場を見るという実習がありましたが、その時に救急隊の方からはじめに言われた注意事項を思い出しました。
曰く、「先生方が病院にいたら感じないかもしれませんが、市民の権利意識が厳しく、救急の現場でも、ガラスが飛び散っているような場所で靴を脱がずにけが人のところに向かったのを、土足で家に上がられたとクレームつけられたり、担架に患者さんを乗せて運んでいるときに、道をあけてもらおうとしたのを、患者の家族を突き飛ばしたとクレームつけられたりすることがあるので、患者さん以上に周りの人に注意して行動してください」
その当時はそうだったかもしれませんが、今では病院にいる先生方も市民の権利意識を感じる機会は多くなっているかもしれません。
前回の記事では厳密にはWatsonの機能を試すところまではやっていなくて、その環境を試したところまででした。きょうは例題のtutorialを見ながら、Watsonのチャットボットとの単純な会話をするところを試してみました。

この画面からログインします。次の画面でcreate+をタップしてworkspaceを作成します。
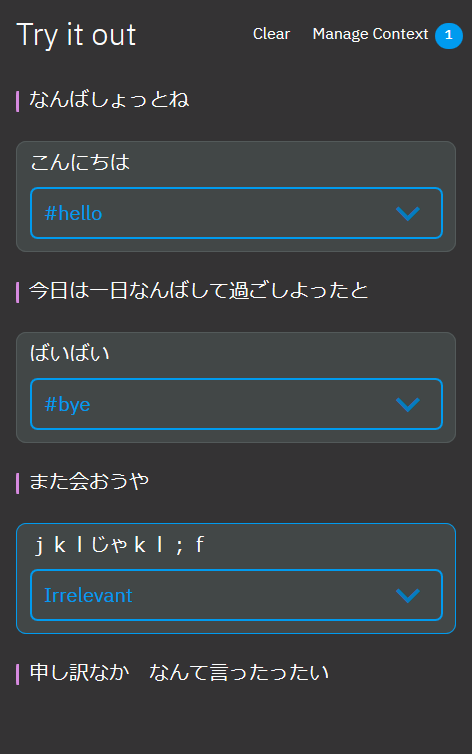
この画面からintentsを作成します。出来上がったいくつかの単純intentsを組み合わせました。試した結果が次です。左側に縦の赤い棒線が入っているのがWatsonがしゃべっている言葉です。
幼い頃大好きだった「トムとジェリー」の音楽をベルリンフィルの演奏で(動画は広告のスネークプレビューです)。それにしても、犬の鳴き声をこんな風にやっていたとは。
「ららら…」で取り上げられるとこちらに訪問する方が一定程度いらっしゃるので、オリジナルのリンクも張っておきます。デジタルコンサートホールで表示すると日本からは権利の関係でこのコンサートを見ることができない旨の警告が表示されます。他の権利者が配信しているはずですが、どこで見ることができるのか私は把握しておりません。
Podcast: Play in new window | Download

特に芸もなく月のアップを投稿します。帰宅途中、ビルの隙間に顔を出した時が大きさを実感できた瞬間なのですが、家に帰ってデジカメを取り出した時には、すでに天空に上がっていました。(Nicon D50, Af niccor 300mm Mモード F8 250 ISO 200 ホワイトバランスはオート) 撮影後にgimpでトリミング、グレー化しました。
2017年ももうすぐ終わりです。
・ 入社以来、ずっと可愛がっていただいていた元上司のAさんが職場を去ったのが何よりも残念です。難しい職場をよくまとめてくださっていただけに、今の職場の今後が心配です。(Aさんは、おそらくどこにいっても通じる様な実力者なので心配はしていません。)
・ 一方、今年はCirculation, Bone Marrow Transplantation, JAMA, Annals of Internal Medicine 誌に記事が掲載され、特にCirculation 誌はpeer reviewのあるページにfirst authorとしての掲載でした。また、これとは別のoncology領域のtop journalにもacceptされている記事があり、これもpeer reviewのあるページです。自分のリサーチがそれなりの評価を得たことで自信を持てます。
2018年みなさまのご多幸を祈念します。今後ともよろしくお願いいたします。