データの保存
データの保存場所、保存形式についてまとめておきます。
データの保存場所
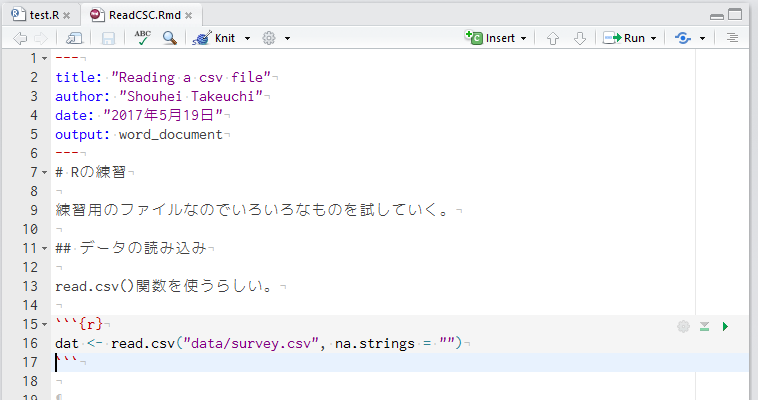
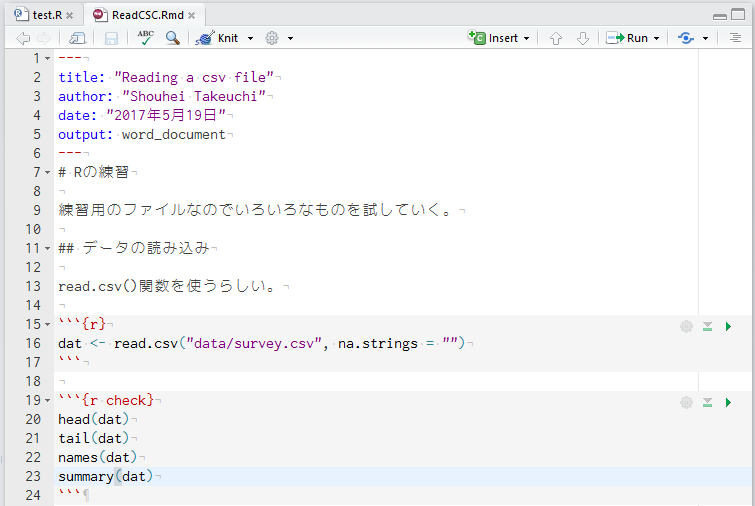
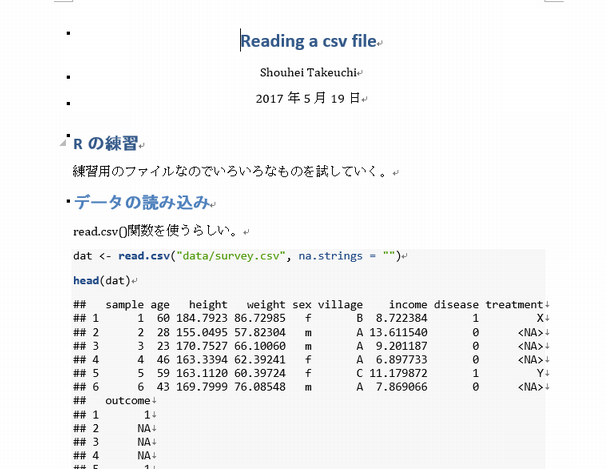
データの読み込むとき、データの保存場所が決まっているとすっきりしますし、余計なトラブルが減ります。おすすめは、プロジェクト内にdataという名前のフォルダを作成(*)し、データを保存しておくことです。
もちろん、名前は何でもいいのですが、わかりやすい名前にしておいた方が後々の管理が楽になります。
データの保存形式
保存するデータは、CSVファイルとし、元データだけを保存することをおすすめします。解析が進むと、データのサブセットをそれぞれファイルに保存したくなることも多いですが、どのようにサブセットを作ったかは、Rのコードに記述しておいた方が、Reproducibilityが高くなり、後々の見直しに役立ちます。
Excel形式のデータを扱うことは可能ですし、一昔前に比べると、ずいぶんと容易になってきました。しかしながら、CSV形式のようにテキスト形式にしておくと、データ自体もgitを用いた管理が可能になってきますので、ぜひCSV形式で保存することをおすすめします。
CSV形式のファイル
データの入力までの間、Excel形式で保存しておくことはかまいませんし、(入力可能な値の範囲の指定など)Excelの機能を使うことで、入力ミスが減るようなことも多いです。最後の保存のところで、CSVファイルに変更すれば十分だと思います。
- ファイル→名前をつけて保存
- Excel ブック(*.xlsx)となっているところをプルダウン→CSV(コンマ区切り)(*.csv)を選択
- 注意点
- ファイル名、変数名、値は半角英数が望ましい。
- (特に全角)スペースは使わないことが望ましい。
- 保存フォルダのパスも注意した方がよい。(プロジェクトを作成しているフォルダのパスを注意していれば問題ない。)
- 欠損値の入力は統一した形式で行う。(空白にするのか「.」を入れるのかなど)