
(Gemini 1.5 Pro) あなたはProのWEBライターです。以下のコードを紹介する記事を書いて。音声の文字起こし前のノイズ除去と正規化をしてくれるコードの紹介です。Pythonをまだ触ったことがない人にもわかるように解説してください。
音声データを文字起こしする際、ノイズや音量のばらつきは悩みの種ですよね。特に大量のファイル処理には、事前準備が欠かせません。
そこで今回は、前回[1]Excel で作った表で誤字を一括修正 (Google Colab). https://plaza.umin.ac.jp/shoei05/index.php/2024/05/25/2518/ に引き続き、Google Colaboratory (Colab) とPythonを使って音声ファイルのノイズ除去と音量正規化を自動で行う方法をご紹介します。
GitHubはこちらです[2]https://github.com/shoei05/soundfile_normalization/
最初に
GPTでも同様にノイズ除去と正規化をやってくれるボットを作成しました。「何から始めたらいい?」を押して指示に従ってください。
https://chatgpt.com/g/g-blH6IXYg6-soundfile-normalization
1. 手順
- Colab を実行
- 音声データをアップロード (“.wav”, “.mp3”, “.mp4”, “.m4a”, “.mkv”, “.webm” に対応しています)
- 自動でノイズ除去、音声の正規化を実行
- 処理後の音声データが自動でダウンロード
ノイズ除去について
音声データには、周囲の環境音や機器のノイズなど、目的とする音声以外の音が含まれていることがよくあります。これらのノイズは、音声認識や分析の精度を低下させる要因となります。そこで、ノイズ除去はクリアな音声データを得るための重要なプロセスです。
ノイズ除去は、音声データから不要なノイズを識別し、除去する処理を指します。さまざまな手法がありますが、多くの場合、音声とノイズの周波数特性の違いを利用したり、機械学習を用いてノイズパターンを学習し除去したりします。
今回のコードでは、 FFmpeg の afftdn フィルターを用いてノイズ除去を行っています。
denoise_command = f"ffmpeg -i {temp_wav} -af 'afftdn=nr={noise_reduction_db}' {temp_denoised} -y"
if os.system(denoise_command) != 0:
raise RuntimeError(f"Error executing ffmpeg command: {denoise_command}")Code language: JavaScript (javascript)afftdn は Adaptive Frequency Domain Noise Reduction の略で、音声とノイズの周波数特性の違いを利用してノイズを除去するフィルターです。 nr パラメータでノイズ除去の強度を指定しており、値が大きいほどノイズ除去が強くなります。
今回の設定では、noise_reduction_db = 10 と設定されています。これは、ノイズ除去の強度を 10dB に設定していることを意味します。 適切なノイズ除去の強度は、音声データのノイズレベルや種類によって異なります。
音量正規化
音声正規化は、音量レベルを調整する処理です。異なる録音環境や機器によって音量レベルが異なる場合があり、そのままでは聞き取りにくい、あるいは音声認識で正確に処理できない可能性があります。音声正規化によって、適切な音量レベルに統一することで、聞き取りやすさと処理の精度を向上させることができます。
このコードでは、pydubライブラリのnormalize関数を用いて音声正規化を行っています。この関数は、入力された音声信号のピークレベルを検出し、それを0dBFS(decibels relative to full scale、フルスケールを基準としたデジベル)に調整することで、可能な限り大きな音量にします。
# 音声の正規化
normalized_audio = normalize(audio)Code language: PHP (php)これらのパラメータにより、放送規格などでも用いられる、聞きやすく、レベルの揃った音声データを作成することができます。
2. Colab でコードを実行
以下のGoogle Colabをご自身のDriveにコピーを保存後してください。
GoogleColabについてもっと知りたい方は、東京大学 数理・情報教育研究センターが公開している「Pythonプログラミング入門」[3]東京大学 数理・情報教育研究センター. Python プログラミング入門. https://utokyo-ipp.github.io/ を参照してください。
https://colab.research.google.com/drive/1S9gfGZZ2NleEv6QgH51dxu2s95sOfgQ2?usp=sharing
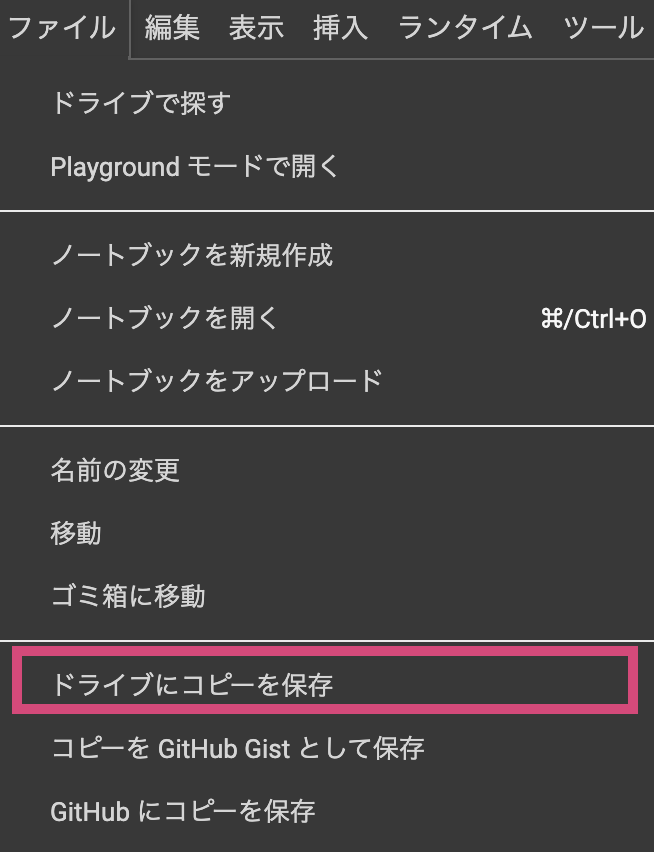
コピーが完了したら、再生ボタンを押してコードを実行してください。

しばらくするとコードブロックの下のほうに「音声データをアップロードしてください」と表示されるので、音声データ(“.wav”, “.mp3”, “.mp4”, “.m4a”, “.mkv”, “.webm”)をアップロードしてください。動画データでも処理可能です。
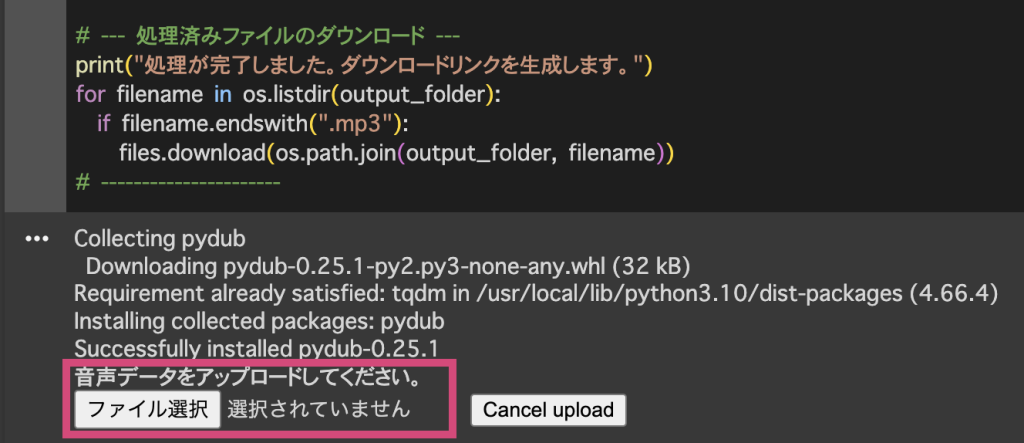
しばらくすると処理が完了して自動でダウンロードが始まります。
Colab で実行する .ipynb コード
!pip install pydub tqdm
import os
from pydub import AudioSegment
from tqdm import tqdm
import logging
from concurrent.futures import ThreadPoolExecutor
import shutil
import tempfile
import uuid
import ipywidgets as widgets
from google.colab import files
# ログの設定
logging.basicConfig(filename='preprocessing.log', level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
def replace_spaces(filename):
return filename.replace(" ", "_")
def preprocess_audio(input_path, output_path, noise_reduction_db, done_folder):
try:
if not os.path.exists(input_path):
raise FileNotFoundError(f"Input file not found: {input_path}")
temp_dir = tempfile.gettempdir()
temp_id = str(uuid.uuid4())
temp_wav = os.path.join(temp_dir, f"temp_{temp_id}.wav")
temp_denoised = os.path.join(temp_dir, f"temp_denoised_{temp_id}.wav")
temp_normalized = os.path.join(temp_dir, f"temp_normalized_{temp_id}.wav")
_, extension = os.path.splitext(input_path)
extension = extension.lower()
# オーディオファイルを読み込んで一時的にwav形式で保存
audio = AudioSegment.from_file(input_path, format=extension.lstrip('.'))
audio.export(temp_wav, format="wav")
# ノイズ除去
denoise_command = f"ffmpeg -i {temp_wav} -af 'afftdn=nr={noise_reduction_db}' {temp_denoised} -y"
if os.system(denoise_command) != 0:
raise RuntimeError(f"Error executing ffmpeg command: {denoise_command}")
# サンプリングレートの変換と正規化
audio = audio.set_frame_rate(16000)
normalized_audio = normalize(audio)
# 正規化された音声を読み込んでmp3形式で保存
normalized_audio = AudioSegment.from_wav(temp_normalized)
normalized_audio.export(output_path, format="mp3")
# 処理したファイルをdoneフォルダに移動
shutil.move(input_path, os.path.join(done_folder, replace_spaces(os.path.basename(input_path))))
logging.info(f"Preprocessed {input_path}")
except Exception as e:
logging.error(f"Error processing {input_path}: {str(e)}")
raise
finally:
# 一時ファイルを削除
for temp_file in [temp_wav, temp_denoised, temp_normalized]:
if os.path.exists(temp_file):
os.remove(temp_file)
def process_files(input_folder, output_folder, noise_reduction_db, max_workers, done_folder):
audio_files = [f for f in os.listdir(input_folder) if f.lower().endswith((".wav", ".mp3", ".mp4", ".m4a", ".mkv", ".webm"))]
total_files = len(audio_files)
progress_bar = tqdm(total=total_files, unit='file')
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
for filename in audio_files:
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, f"{os.path.splitext(replace_spaces(filename))[0]}.mp3")
futures.append(executor.submit(preprocess_audio, input_path, output_path, noise_reduction_db, done_folder))
for future in futures:
try:
future.result()
progress_bar.update()
except Exception as e:
logging.error(f"Error in parallel processing: {str(e)}")
progress_bar.close()
# --- 音声データファイルのアップロード ---
input_folder = '/content/p_input'
output_folder = '/content/input'
done_folder = '/content/p_done'
os.makedirs(input_folder, exist_ok=True)
os.makedirs(output_folder, exist_ok=True)
os.makedirs(done_folder, exist_ok=True)
while True:
print("音声データをアップロードしてください。")
uploaded = files.upload()
for filename in uploaded.keys():
shutil.move(filename, os.path.join(input_folder, filename))
break
# ----------------------
noise_reduction_db = 10
max_workers = 4
process_files(input_folder, output_folder, noise_reduction_db, max_workers, done_folder)
# --- 処理済みファイルのダウンロード ---
print("処理が完了しました。ダウンロードリンクを生成します。")
for filename in os.listdir(output_folder):
if filename.endswith(".mp3"):
files.download(os.path.join(output_folder, filename))
# ----------------------Code language: PHP (php)自分のローカルPCでPythonで実行する場合
準備
1. Pythonをインストール
まだインストールしていない場合は、Python公式ウェブサイトからダウンロードしてインストールしてください。
コマンドプロンプト/ターミナルを開いて、
- Windows: Windowsキーを押して「cmd」と入力し、Enterキーを押します。
- Mac: Spotlight検索 (虫眼鏡アイコン) をクリックし、「ターミナル」と入力してEnterキーを押します。
python -Vと入力して、
Python 3.12.3Code language: CSS (css)などと表示されていればPythonは既にインストールされています。
ます。
2. 必要なライブラリのインストール
コマンドプロンプトまたはターミナルを開き、以下のコマンドを実行して必要なライブラリをインストールします。
pip install pydub tqdm3. FFmpegのインストール
FFmpeg (エフエフエムペグ) は、動画の編集や変換などが可能なフリーソフト[4]FFmpeg. Accessed May 4, 2021. https://www.ffmpeg.org/ です。
FFmpegのインストール方法は過去に書いた下記記事を参照ください。
4. コードの準備と実行準備
処理したい音声データ (“.wav”, “.mp3”, “.mp4”, “.m4a”, “.mkv”, “.webm”) と下記のコードをコピーして soundfile_normalization.py の名前で保存します。以下の構造で準備してください。
任意のフォルダ
├── soundfile_normalization.py
├── input (フォルダ)
│└── (音声データを入れる)
├── output (コードを実行したら自動で生成されます)
│└── (処理後の音声データが自動で格納されます)
└── done_original (コードを実行したら自動で生成されます)
└── (処理後の元データが自動で格納されます) Code language: CSS (css)GitHubからダウンロードしても構いません。Gitをインストールしている人は、
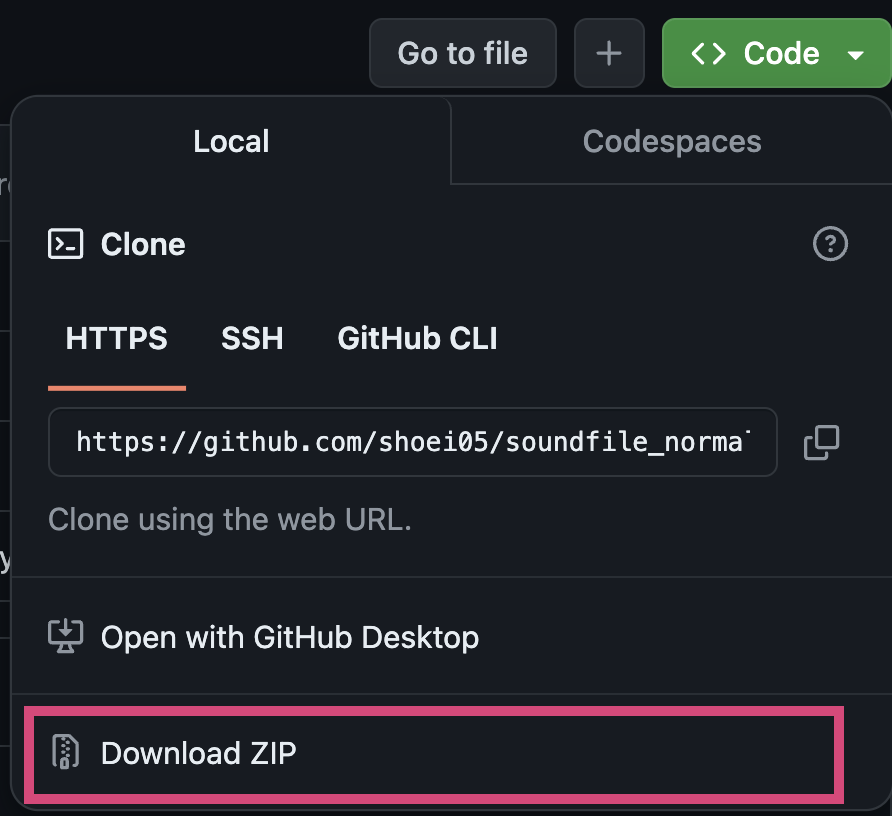
git clone https://github.com/shoei05/soundfile_normalization.gitCode language: PHP (php)でクローンしてください。もしくは、
https://github.com/shoei05/soundfile_normalization/tree/main
から Zip ファイルをダウンロードすることもできます。
Pythonコード
import os
from pydub import AudioSegment
from pydub.effects import normalize
from tqdm import tqdm
import logging
from concurrent.futures import ThreadPoolExecutor
import shutil
import tempfile
import uuid
# ログの設定
logging.basicConfig(filename='preprocessing.log', level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
def replace_spaces(filename):
return filename.replace(" ", "_")
def preprocess_audio(input_path, output_path, noise_reduction_db, done_folder):
try:
if not os.path.exists(input_path):
raise FileNotFoundError(f"Input file not found: {input_path}")
temp_dir = tempfile.gettempdir()
temp_id = str(uuid.uuid4())
temp_wav = os.path.join(temp_dir, f"temp_{temp_id}.wav")
temp_denoised = os.path.join(temp_dir, f"temp_denoised_{temp_id}.wav")
_, extension = os.path.splitext(input_path)
extension = extension.lower()
# オーディオファイルを読み込んで一時的にwav形式で保存
audio = AudioSegment.from_file(input_path, format=extension.lstrip('.'))
audio.export(temp_wav, format="wav")
# ノイズ除去
denoise_command = f"ffmpeg -i {temp_wav} -af 'afftdn=nr={noise_reduction_db}' {temp_denoised} -y"
if os.system(denoise_command) != 0:
raise RuntimeError(f"Error executing ffmpeg command: {denoise_command}")
# ノイズ除去後の音声を読み込み
audio = AudioSegment.from_wav(temp_denoised)
# サンプリングレートの変換
audio = audio.set_frame_rate(16000)
# 音声の正規化
normalized_audio = normalize(audio)
# 正規化された音声を読み込んでmp3形式で保存
normalized_audio.export(output_path, format="mp3")
# 処理したファイルをdoneフォルダに移動
shutil.move(input_path, os.path.join(done_folder, replace_spaces(os.path.basename(input_path))))
logging.info(f"Preprocessed {input_path}")
except Exception as e:
logging.error(f"Error processing {input_path}: {str(e)}")
raise
finally:
# 一時ファイルを削除
for temp_file in [temp_wav, temp_denoised]:
if os.path.exists(temp_file):
os.remove(temp_file)
def process_files(input_folder, output_folder, noise_reduction_db, max_workers, done_folder):
audio_files = [f for f in os.listdir(input_folder) if f.lower().endswith((".wav", ".mp3", ".mp4", ".m4a", ".mkv", ".webm"))]
total_files = len(audio_files)
progress_bar = tqdm(total=total_files, unit='file')
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
for filename in audio_files:
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, f"{os.path.splitext(replace_spaces(filename))[0]}.mp3")
futures.append(executor.submit(preprocess_audio, input_path, output_path, noise_reduction_db, done_folder))
for future in futures:
try:
future.result()
progress_bar.update()
except Exception as e:
logging.error(f"Error in parallel processing: {str(e)}")
progress_bar.close()
if __name__ == "__main__":
input_folder = './p_input'
output_folder = './input'
done_folder = './p_done'
noise_reduction_db = 10
max_workers = 4
os.makedirs(output_folder, exist_ok=True)
os.makedirs(done_folder, exist_ok=True)
process_files(input_folder, output_folder, noise_reduction_db, max_workers, done_folder)Code language: PHP (php)5. 実行
コマンドプロンプト/ターミナルで、cd コマンドを使ってreplace_text.pyファイルがあるディレクトリに移動します。前回の記事も参照して下さい。
以下のコマンドを実行します。
python sound_normalization.pyCode language: CSS (css)処理が完了すると、output フォルダが自動生成され、処理後の音声データが .mp3 形式で格納されています。処理前のデータは input_original フォルダに格納されています。
この処理は並列で処理が可能です。実行したい音声データをフォルダにまとめていれてからコードを実行すると、一括でノイズ除去と正規化が完了します。
まとめ
今回は、私が普段使いしているPythonコードの紹介第2段として、音声データのノイズ除去と音量正規化を自動化する手法を紹介しました。
音声データの質を向上させることは、文字起こしの精度向上に直結するだけでなく、音声認識を使ったシステム開発や、より快適な音声コンテンツの提供にも役立ちます。ぜひ、今回ご紹介したコードを参考に、ご自身の環境で試してみてください。
References
| ↑1 | Excel で作った表で誤字を一括修正 (Google Colab). https://plaza.umin.ac.jp/shoei05/index.php/2024/05/25/2518/ |
|---|---|
| ↑2 | https://github.com/shoei05/soundfile_normalization/ |
| ↑3 | 東京大学 数理・情報教育研究センター. Python プログラミング入門. https://utokyo-ipp.github.io/ |
| ↑4 | FFmpeg. Accessed May 4, 2021. https://www.ffmpeg.org/ |